Einführung
Die Sichtung von Lebensläufen ist einer der zeitaufwändigsten Aspekte des Einstellungsprozesses. HR-Teams verbringen oft Stunden damit, Lebensläufe zu prüfen, wichtige Informationen zu extrahieren, Kandidaten zu bewerten und Zusammenfassungen für Einstellungsverantwortliche vorzubereiten. In diesem Tutorial bauen wir einen automatisierten Lebenslauf-Analyzer, der diese Arbeit für Sie übernimmt – durch die Kombination von Pipedream-Workflow-Automatisierung, Claude AI für intelligente Analyse und DocuGenerate für professionelle PDF-Generierung.
Der Workflow wird automatisch ausgelöst, sobald ein neuer Lebenslauf zu einem Dropbox-Ordner hinzugefügt wird. Er extrahiert den Text aus dem Lebenslauf, verwendet Claude, um die Erfahrung und Qualifikationen des Kandidaten zu analysieren, erstellt eine strukturierte Zusammenfassung mit wichtigen Erkenntnissen und generiert einen professionellen PDF-Bericht, den Ihr Einstellungsteam sofort einsehen kann. Der gesamte Prozess dauert nur Sekunden und erfordert keinerlei manuelle Eingriffe.
Dieser Ansatz ist besonders wertvoll für Unternehmen, die mehrere Lebensläufe schnell verarbeiten müssen und dabei Konsistenz bei der Kandidatenbewertung wahren wollen. Durch die Standardisierung des Analyseformats und den Einsatz von KI zur Erkenntnisgewinnung können Sie Ihre Zeit dem Interview der vielversprechendsten Kandidaten widmen, anstatt Stunden mit der Erstprüfung zu verbringen.
Den Workflow Verstehen
Der vollständige Workflow besteht aus sieben verbundenen Schritten, die gemeinsam einen rohen Lebenslauf in einen strukturierten Analysebericht umwandeln. So verläuft der Prozess von Anfang bis Ende:
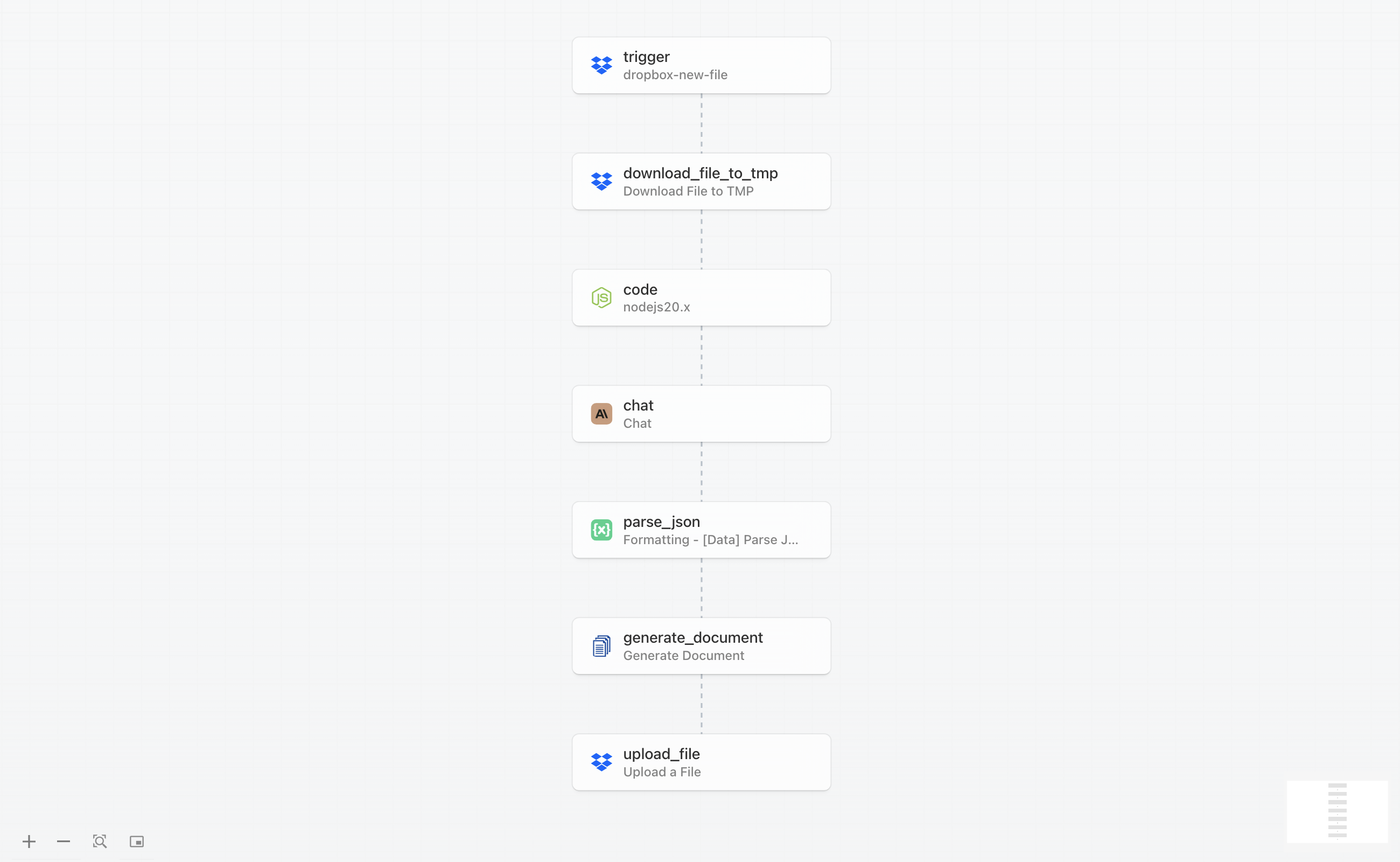
Der Workflow beginnt, wenn Sie einen Lebenslauf in einen überwachten Dropbox-Ordner hochladen. Pipedream erkennt die neue Datei, lädt sie herunter und extrahiert den Textinhalt aus der PDF. Dieser Text wird dann mit spezifischen Anweisungen an Claude AI gesendet, um den Lebenslauf zu analysieren und wichtige Informationen wie Berufserfahrung, Fähigkeiten, Ausbildung und bemerkenswerte Leistungen zu extrahieren. Claude gibt eine strukturierte JSON-Antwort zurück, die alle extrahierten Daten enthält.
Die JSON-Daten werden dann zusammen mit einer vorab gestalteten Vorlage an DocuGenerate übergeben, um eine professionelle PDF-Zusammenfassung zu generieren. Sobald das Dokument erstellt ist, wird es automatisch in einen dedizierten Ordner in Dropbox hochgeladen, wo Ihr Einstellungsteam darauf zugreifen kann. Der gesamte Prozess wird in unter einer Minute abgeschlossen, und Sie können mehrere Lebensläufe gleichzeitig verarbeiten, indem Sie sie einfach in den Auslöser-Ordner hochladen.
Dokumentvorlage Einrichten
Bevor wir den Pipedream-Workflow aufbauen, müssen wir eine Vorlage erstellen, die unsere Lebenslaufanalyse-Berichte formatiert. Die Vorlage verwendet die Merge-Tag-Syntax von DocuGenerate, um festzulegen, wo die Daten aus Claudes Analyse im endgültigen Dokument erscheinen sollen. So wird sichergestellt, dass jede Kandidatenzusammenfassung einem konsistenten, professionellen Format folgt.
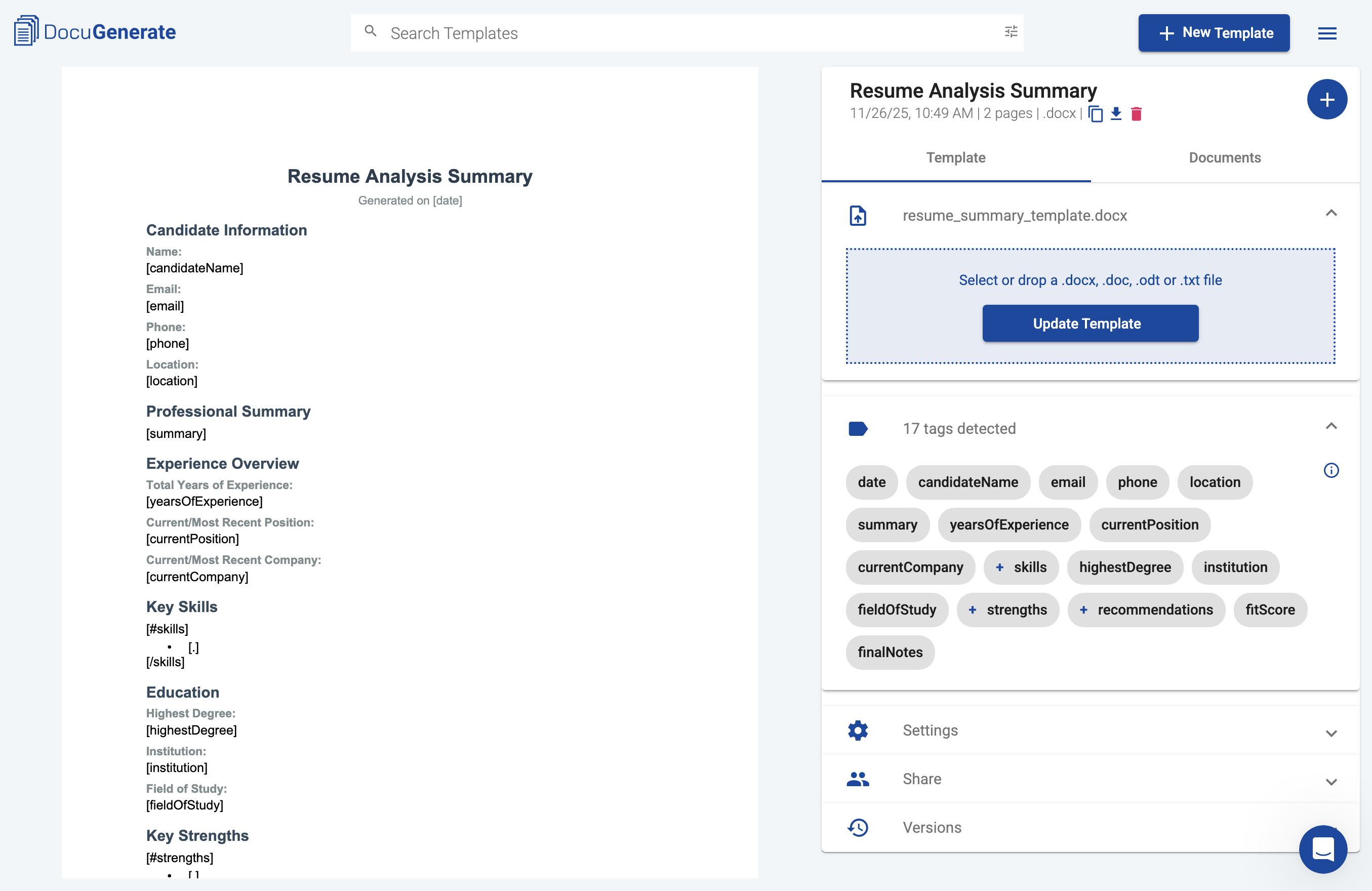
Die Vorlage enthält Abschnitte für Kandidateninformationen (Name, E-Mail, Telefon, Ort), eine berufliche Zusammenfassung, einen Erfahrungsüberblick, wichtige Fähigkeiten, Ausbildung, Stärken, Interviewempfehlungen und eine Gesamtbewertung mit einem Eignungswert. Einige Abschnitte wie Fähigkeiten, Stärken und Empfehlungen verwenden die Listensyntax, um mehrere Elemente aus Arrays in den Daten anzuzeigen. Beispielsweise verwendet der Fähigkeitsabschnitt [#skills], um die Schleife zu beginnen, [.], um jede Fähigkeit als Aufzählungspunkt anzuzeigen, und [/skills], um die Schleife zu beenden.
Sie können die vollständige Vorlage herunterladen und in Ihr DocuGenerate-Konto hochladen. Notieren Sie sich nach dem Hochladen den Vorlagennamen oder die ID, da Sie diese Informationen beim Konfigurieren des Dokumentengenerierungsschritts im Workflow benötigen. Mit der fertigen Vorlage können wir nun den Pipedream-Workflow aufbauen, der den gesamten Analyseprozess automatisiert.
Den Dropbox-Trigger Konfigurieren
Der Workflow beginnt mit einem Dropbox-Trigger, der einen bestimmten Ordner auf neue Dateien überwacht. Dieser Trigger ist der Einstiegspunkt, der die gesamte Automatisierung aktiviert, sobald ein Lebenslauf hochgeladen wird. Um diesen Trigger zu konfigurieren, müssen Sie Ihr Dropbox-Konto mit Pipedream verbinden und angeben, welchen Ordner überwacht werden soll.
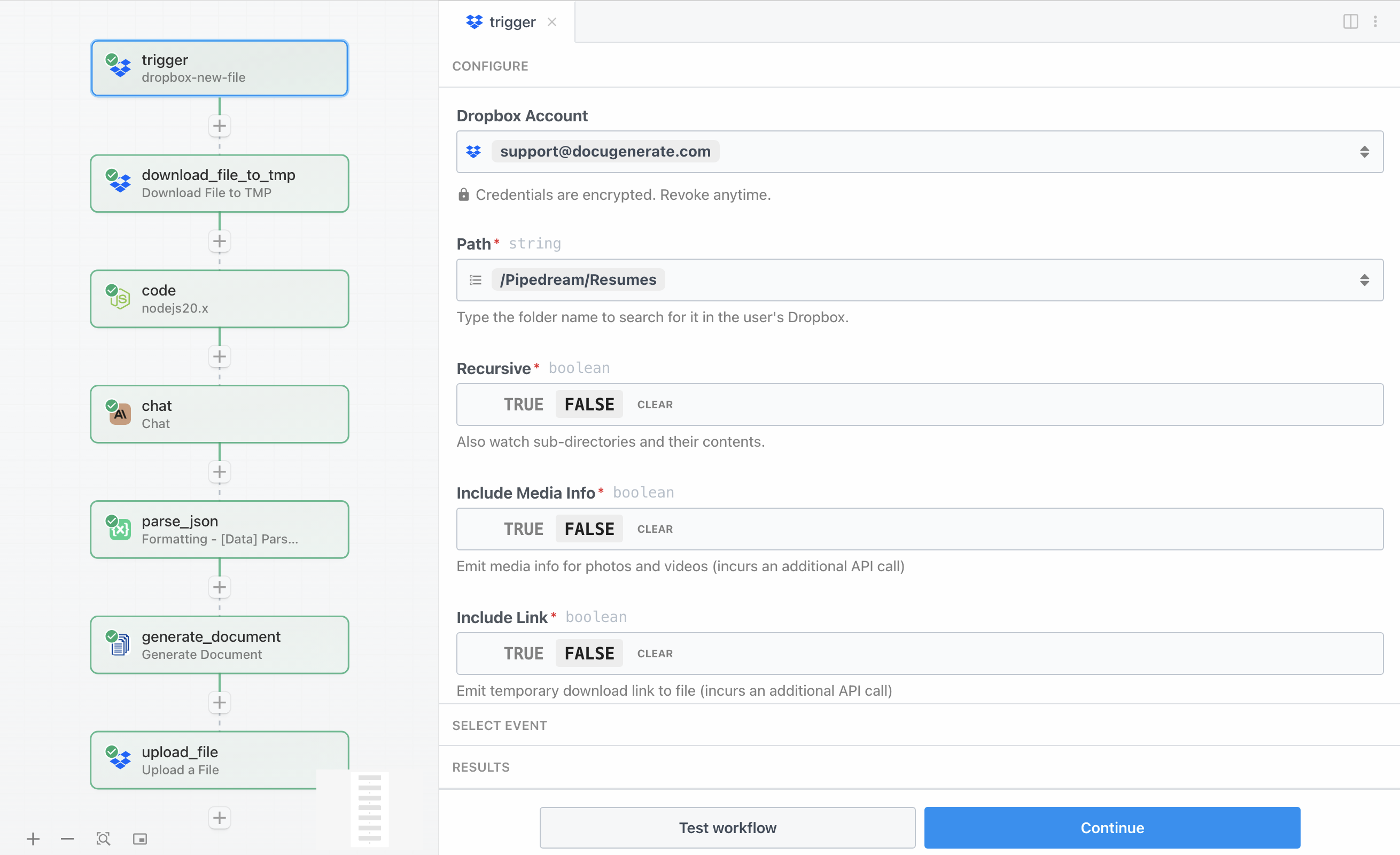
Für dieses Tutorial überwachen wir einen Ordner namens /Pipedream/Resumes. Wenn Sie den Trigger mit einem Beispiel-Lebenslauf testen, sehen Sie, dass er Metadaten zur Datei zurückgibt, darunter Dateiname, Pfad, Größe und Änderungsdaten. Es ist jedoch wichtig zu beachten, dass der Trigger nur diese Metadaten und nicht den eigentlichen Dateiinhalt liefert. Deshalb benötigen wir einen separaten Schritt zum Herunterladen der Datei, den wir im nächsten Abschnitt konfigurieren.
Der Trigger wird sofort aktiviert, wenn eine neue Datei erkannt wird, sodass der Workflow schnell auf Ihre Einstellungsanforderungen reagiert. Sie können den ganzen Tag über Lebensläufe hochladen, und jeder wird automatisch verarbeitet, ohne manuellen Eingriff. Diese Echtzeit-Verarbeitung stellt sicher, dass Kandidatenzusammenfassungen so schnell wie möglich für Ihr Team verfügbar sind.
Die Lebenslauf-Datei Herunterladen
Nachdem der Trigger eine neue Datei erkannt hat, müssen wir den Dateiinhalt tatsächlich herunterladen, bevor wir Text daraus extrahieren können. Die Aktion Download File to TMP ruft den Lebenslauf aus Dropbox ab und speichert ihn im temporären Speicher von Pipedream, wo nachfolgende Schritte darauf zugreifen können.
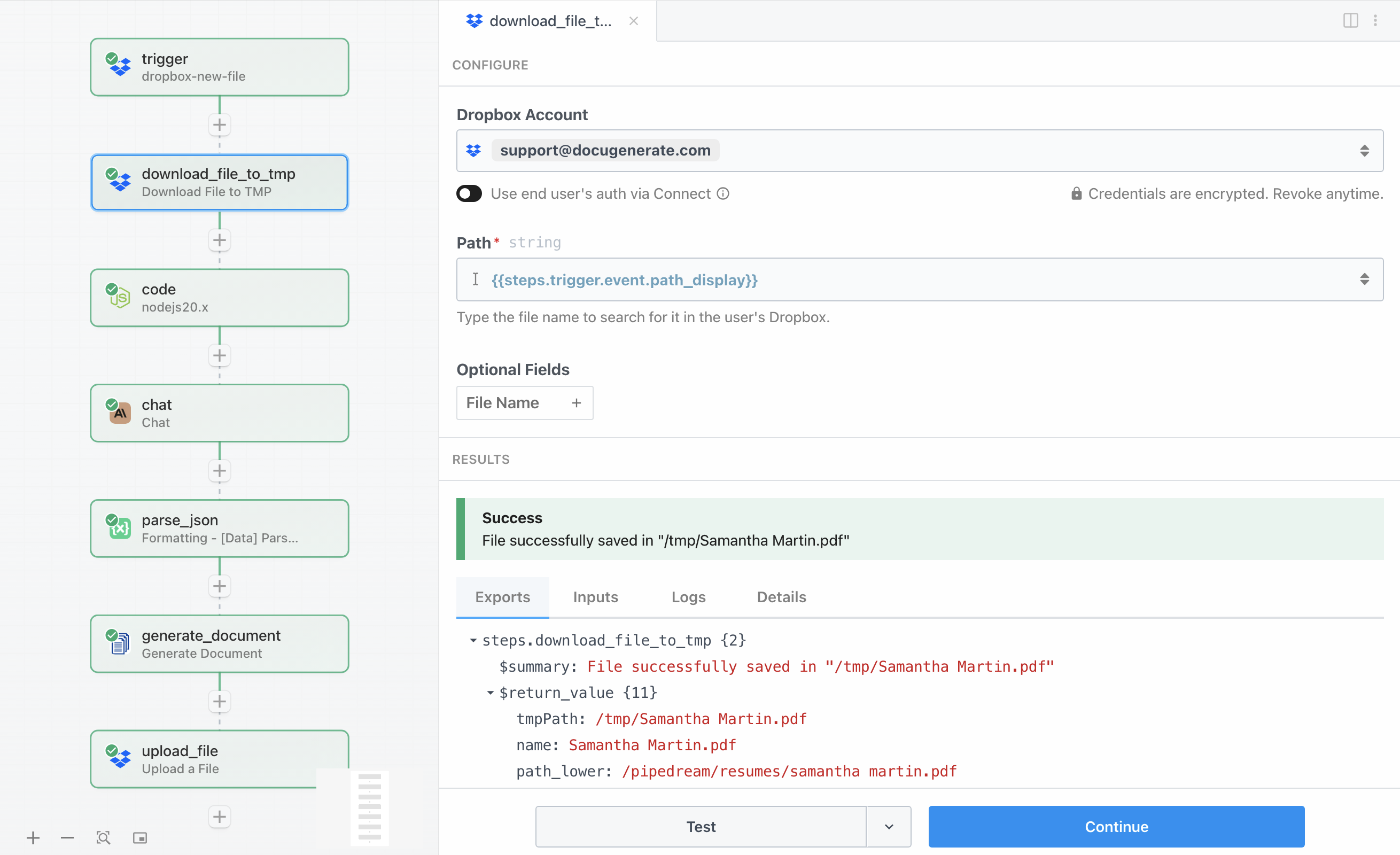
Die Konfiguration ist unkompliziert. Der Parameter Path verwendet {{steps.trigger.event.path_display}}, um den vom Trigger erfassten Dateipfad zu referenzieren. Diese Aktion lädt die Datei herunter und gibt ein Objekt zurück, das den temporären Dateipfad in der Eigenschaft tmpPath enthält. Die Datei verbleibt während der gesamten Workflow-Ausführung im temporären Speicher, was sich ideal zum Verarbeiten und anschließenden Verwerfen eignet.
Die heruntergeladene Datei ist nun für die Textextraktion bereit. Der temporäre Dateipfad wird im nächsten Schritt verwendet, um den PDF-Inhalt zu lesen und in Text umzuwandeln, den Claude analysieren kann.
Da der Lebenslauf nun im temporären Speicher liegt, müssen wir den Textinhalt aus der PDF-Datei extrahieren. Dieser Schritt verwendet einen Node.js-Codeblock mit der Bibliothek pdf-parse, um die PDF zu lesen und in Klartext umzuwandeln, den Claude analysieren kann.
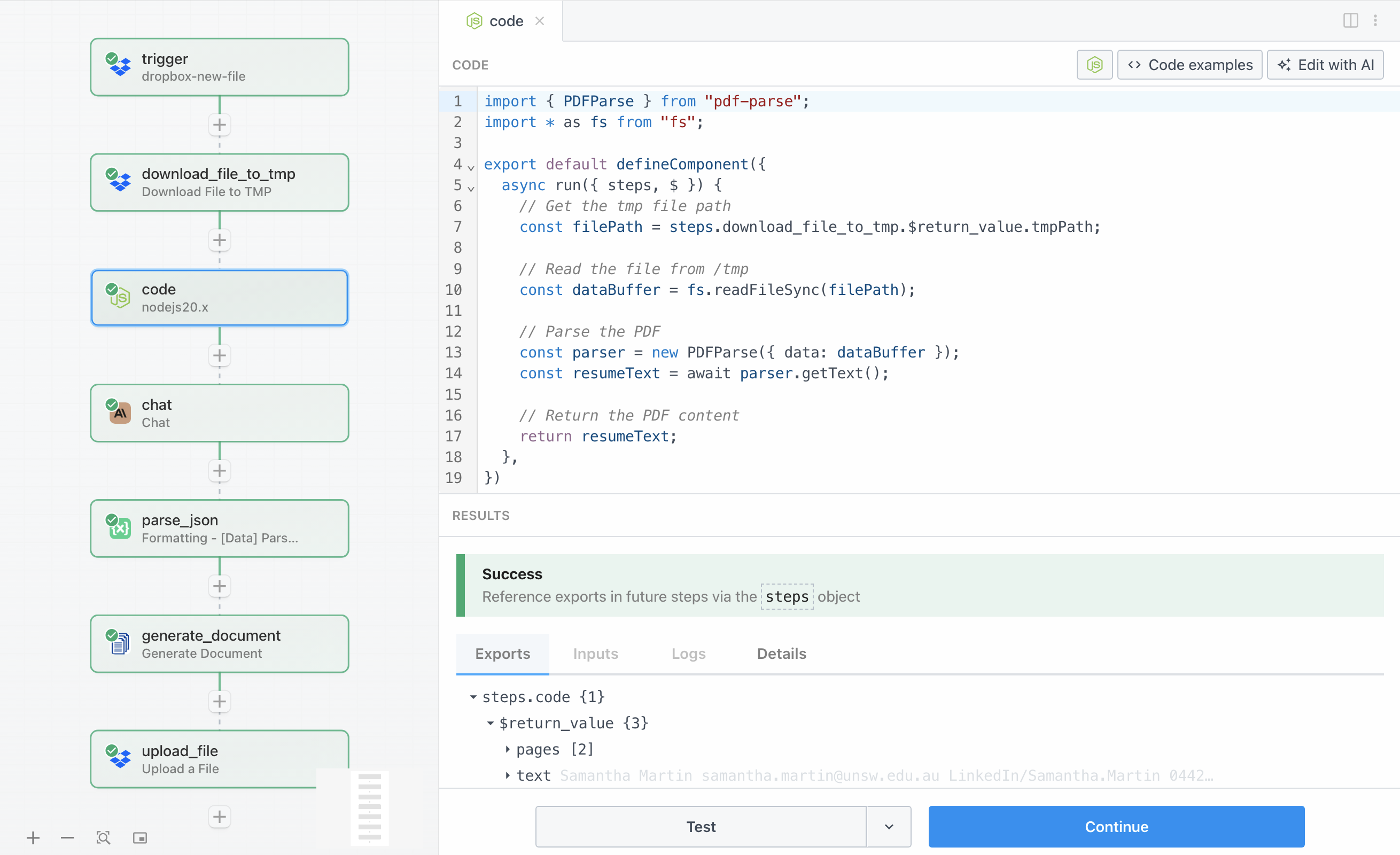
Der Code liest die Datei aus dem temporären Pfad mit dem integrierten fs-Modul von Node.js und übergibt dann den Datei-Buffer an pdf-parse zur Verarbeitung. Die Bibliothek übernimmt die komplexe PDF-Verarbeitung und gibt den extrahierten Text als Zeichenkette zurück.
import { PDFParse } from "pdf-parse";
import * as fs from "fs";
export default defineComponent({
async run({ steps, $ }) {
// Get the tmp file path
const filePath = steps.download_file_to_tmp.$return_value.tmpPath;
// Read the file from /tmp
const dataBuffer = fs.readFileSync(filePath);
// Parse the PDF
const parser = new PDFParse({ data: dataBuffer });
const resumeText = await parser.getText();
// Return the PDF content
return resumeText;
},
})
Der extrahierte Text steht nun in resumeText zur Verfügung und ist bereit, im nächsten Schritt von Claude analysiert zu werden.
Den Lebenslauf mit Claude Analysieren
Hier geschieht die eigentliche Intelligenz. Der Claude-API-Schritt sendet den extrahierten Lebenslauftext an Anthropics Claude AI mit detaillierten Anweisungen, den Inhalt zu analysieren und strukturierte Daten im JSON-Format zurückzugeben. Claude untersucht den Lebenslauf und extrahiert wichtige Informationen wie Berufserfahrung, Fähigkeiten, Ausbildung und liefert Erkenntnisse, die normalerweise eine manuelle Prüfung erfordern würden.
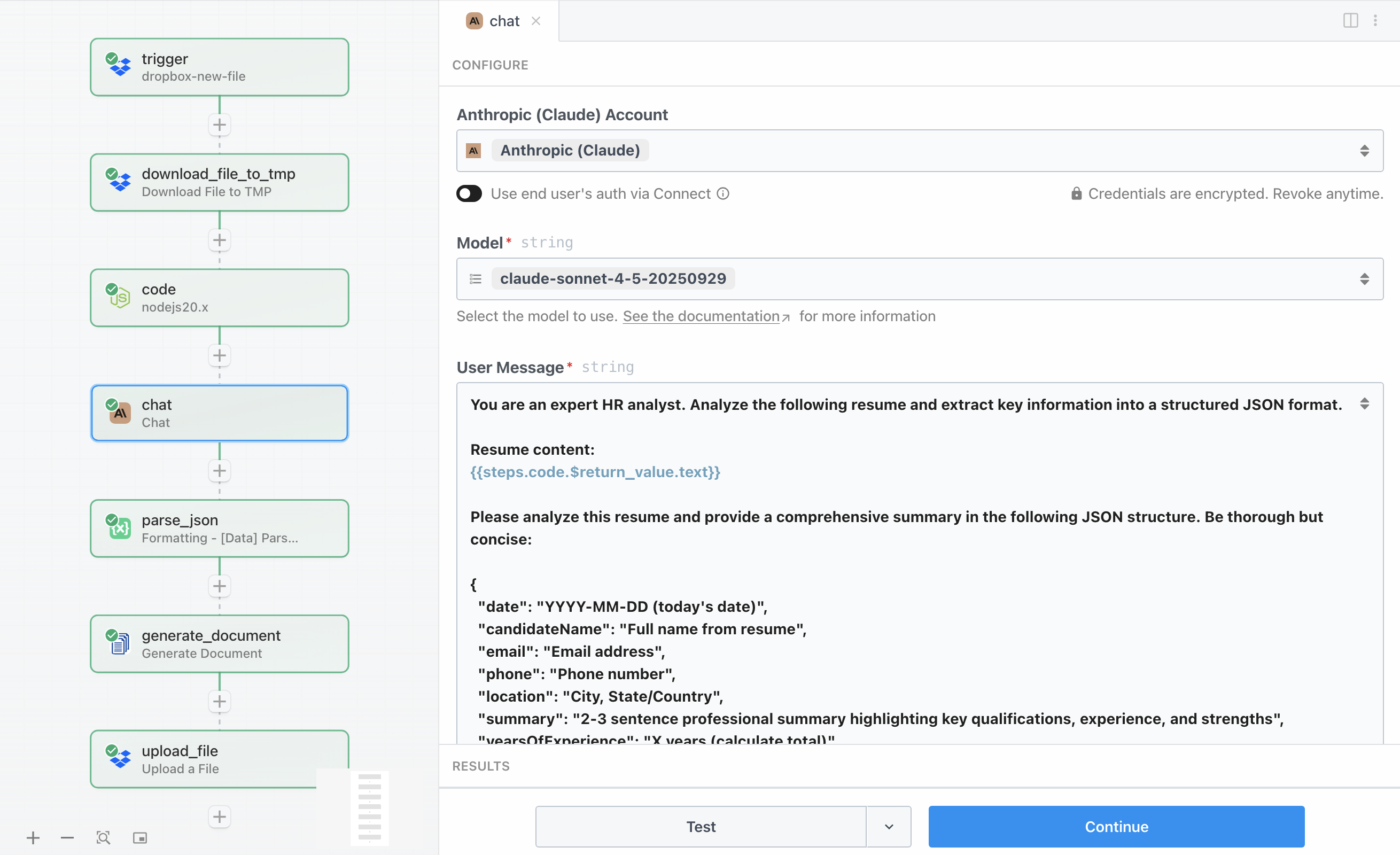
Für die Konfiguration der Aktion Chat with Anthropic (Claude) benötigen Sie Ihren Anthropic-API-Schlüssel, den Sie in Ihrem Anthropic-Konto erhalten. Die Anfrage verwendet das Modell claude-sonnet-4-5-20250929, das eine ausgezeichnete Balance aus Geschwindigkeit, Kosten und Analysefähigkeit für diese Aufgabe bietet. Der Parameter Maximum Tokens to Sample ist auf 4096 gesetzt, was Claude genug Raum gibt, eine umfassende Analyse mit allen benötigten Feldern zurückzugeben.
Der Prompt ist sorgfältig strukturiert, um Claude anzuleiten, spezifische Informationen zu extrahieren und diese als gültiges JSON zu formatieren. Hier ist der vollständige Prompt, der Claude anweist, was zu analysieren ist und wie die Antwort strukturiert werden soll:
You are an expert HR analyst. Analyze the following resume and extract key information into a structured JSON format.
Resume content:
{{steps.code.$return_value.text}}
Please analyze this resume and provide a comprehensive summary in the following JSON structure. Be thorough but concise:
{
"date": "YYYY-MM-DD (today's date)",
"candidateName": "Full name from resume",
"email": "Email address",
"phone": "Phone number",
"location": "City, State/Country",
"summary": "2-3 sentence professional summary highlighting key qualifications, experience, and strengths",
"yearsOfExperience": "X years (calculate total)",
"currentPosition": "Most recent job title",
"currentCompany": "Most recent company name",
"skills": [
"List 6-10 key technical and professional skills with proficiency levels where relevant"
],
"highestDegree": "Degree name (e.g., Bachelor of Science in Computer Science)",
"institution": "University/College name",
"fieldOfStudy": "Major/Field",
"strengths": [
"List 4-6 key strengths based on achievements, projects, and experience"
],
"recommendations": [
"List 4-5 specific interview questions or topics to explore based on their unique experience"
],
"fitScore": "Rate 1-10 based on overall qualifications and experience",
"finalNotes": "2-3 sentence overall assessment and hiring recommendation"
}
IMPORTANT INSTRUCTIONS:
- Extract all information directly from the resume
- If any field is not available in the resume, use "Not specified" or an empty array []
- For skills, include proficiency levels when they can be inferred from years of experience or explicit mentions
- Make the summary compelling but accurate
- Base the fitScore on years of experience, skill diversity, education, and career progression
- Ensure all JSON is properly formatted with no syntax errors
- Return ONLY the JSON object, no additional text or markdown formatting
CRITICAL OUTPUT REQUIREMENTS:
- Return ONLY the raw JSON object
- Do NOT wrap the JSON in markdown code blocks
- Do NOT include ```json or ``` markers
- Do NOT add any explanatory text before or after the JSON
- The response must start with { and end with }
- The entire response must be valid, parseable JSON
Claude verarbeitet den Lebenslauftext und gibt ein JSON-Objekt zurück, das alle extrahierten Informationen enthält. Die Antwort umfasst alles von grundlegenden Kontaktdaten bis hin zu aufschlussreichen Empfehlungen für Interviewfragen, die auf der einzigartigen Erfahrung des Kandidaten basieren. Dieses strukturierte Format erleichtert die Übergabe der Daten an DocuGenerate zur Dokumentengenerierung im nächsten Schritt.
Die JSON-Antwort Parsen
Claude gibt seine Analyse als JSON-Zeichenkette zurück, aber wir müssen diese in ein strukturiertes Objekt umwandeln, mit dem wir in nachfolgenden Schritten arbeiten können. Die integrierte Parse JSON-Aktion von Pipedream, die unter Formatting → Data zu finden ist, übernimmt diese Umwandlung automatisch.
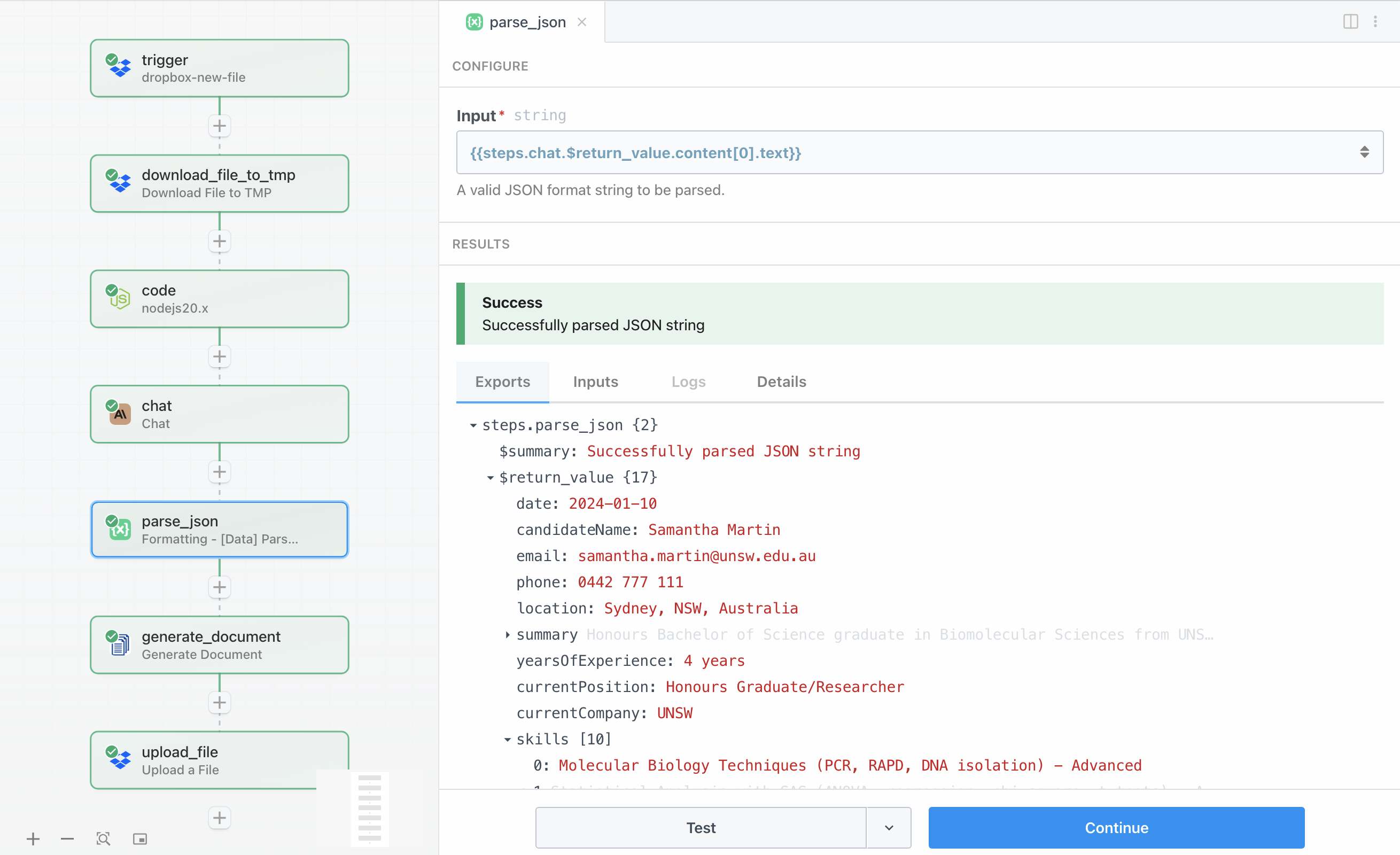
Die Konfiguration nimmt einfach die Claude-Antwort aus {{steps.chat.$return_value.content[0].text}} und parst sie in ein strukturiertes Objekt. Diese geparsten Daten stehen dann allen nachfolgenden Schritten im Workflow zur Verfügung, sodass wir spezifische Felder wie {{steps.parse_json.$return_value.candidateName}} referenzieren können, wenn wir sie benötigen.
Die Aufschlüsselung der Daten in einzelne Felder ist besonders nützlich für dynamische Dateinamen und für die Übergabe des vollständigen Datensatzes an DocuGenerate. Das geparste Objekt enthält alle in unserer Vorlage definierten Felder: Kandidateninformationen, Zusammenfassung, Fähigkeits-Array, Stärken-Array, Empfehlungs-Array und die Gesamtbewertung.
Das Zusammenfassungsdokument Generieren
Da die analysierten Daten nun als strukturiertes Objekt vorliegen, können wir die professionelle PDF-Zusammenfassung generieren. Dieser Schritt verwendet die DocuGenerate App auf Pipedream, um die Daten mit unserer Vorlage zusammenzuführen und ein formatiertes Dokument zu erstellen.
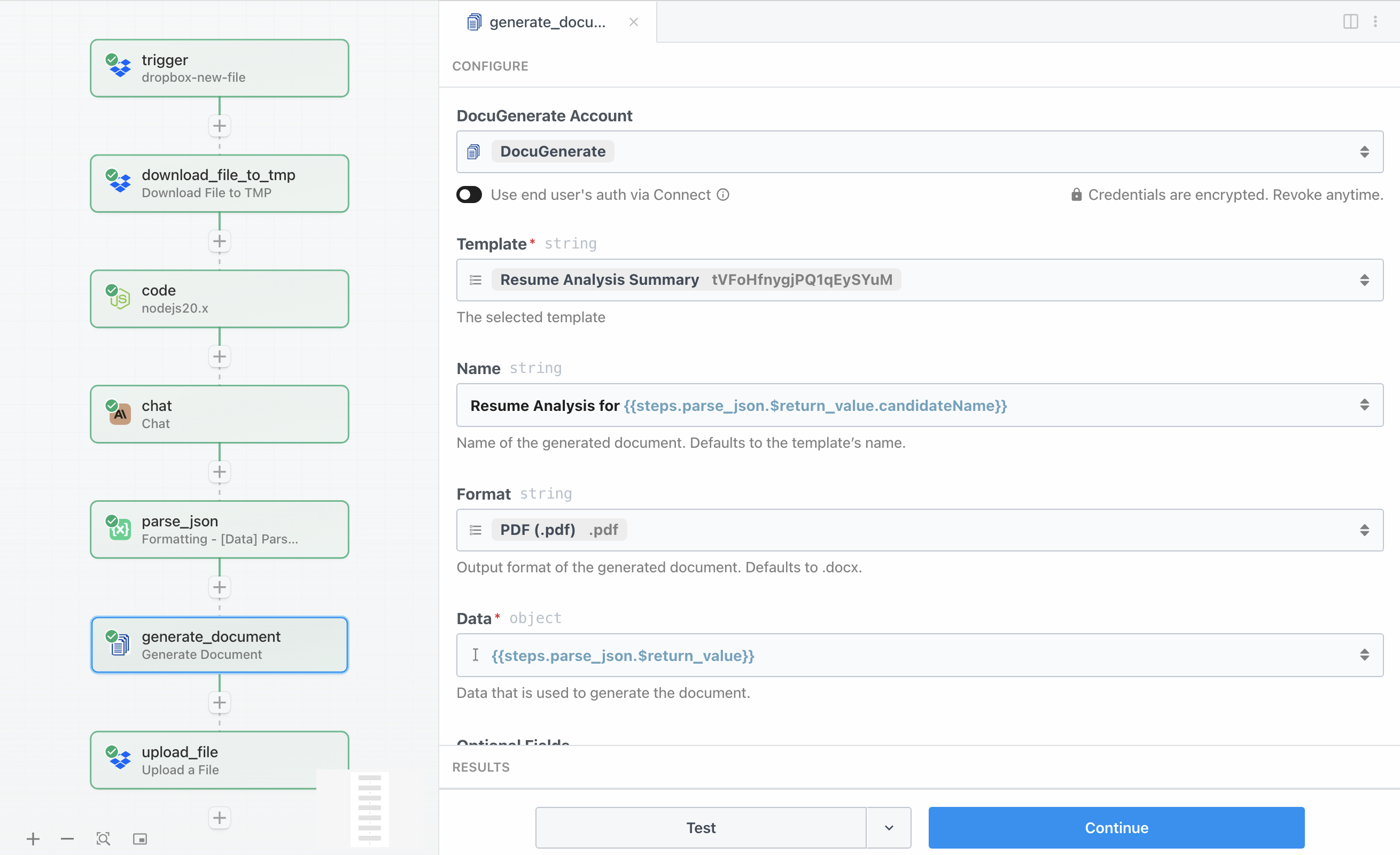
Sie benötigen Ihren DocuGenerate-API-Schlüssel, um eine Verbindung einzurichten, den Sie in Ihren Kontoeinstellungen finden. Die Aktionskonfiguration umfasst mehrere wichtige Parameter:
- Template gibt die Vorlage Resume Analysis Summary aus dem Einrichtungsabschnitt an
- Name verwendet
Resume Analysis for {{steps.parse_json.$return_value.candidateName}}, um einen dynamischen Dateinamen basierend auf dem Namen des Kandidaten zu erstellen - Format ist auf
PDF (.pdf) gesetzt, um ein PDF-Dokument zu generieren - Data enthält das vollständige geparste JSON-Objekt
{{steps.parse_json.$return_value}} von Claude mit allen Kandidateninformationen
Die API verarbeitet diese Anfrage und gibt eine Antwort zurück, die ein Feld document_uri enthält – eine URL, die auf das generierte PDF-Dokument verweist.
Die Analyse in Dropbox Hochladen
Der letzte Schritt schließt den Workflow ab, indem die generierte PDF-Analyse zurück in Dropbox hochgeladen wird, wo Ihr Einstellungsteam darauf zugreifen kann. Die Aktion Upload a File speichert das Dokument in einem dedizierten Ordner und organisiert alle Kandidatenanalysen an einem Ort.
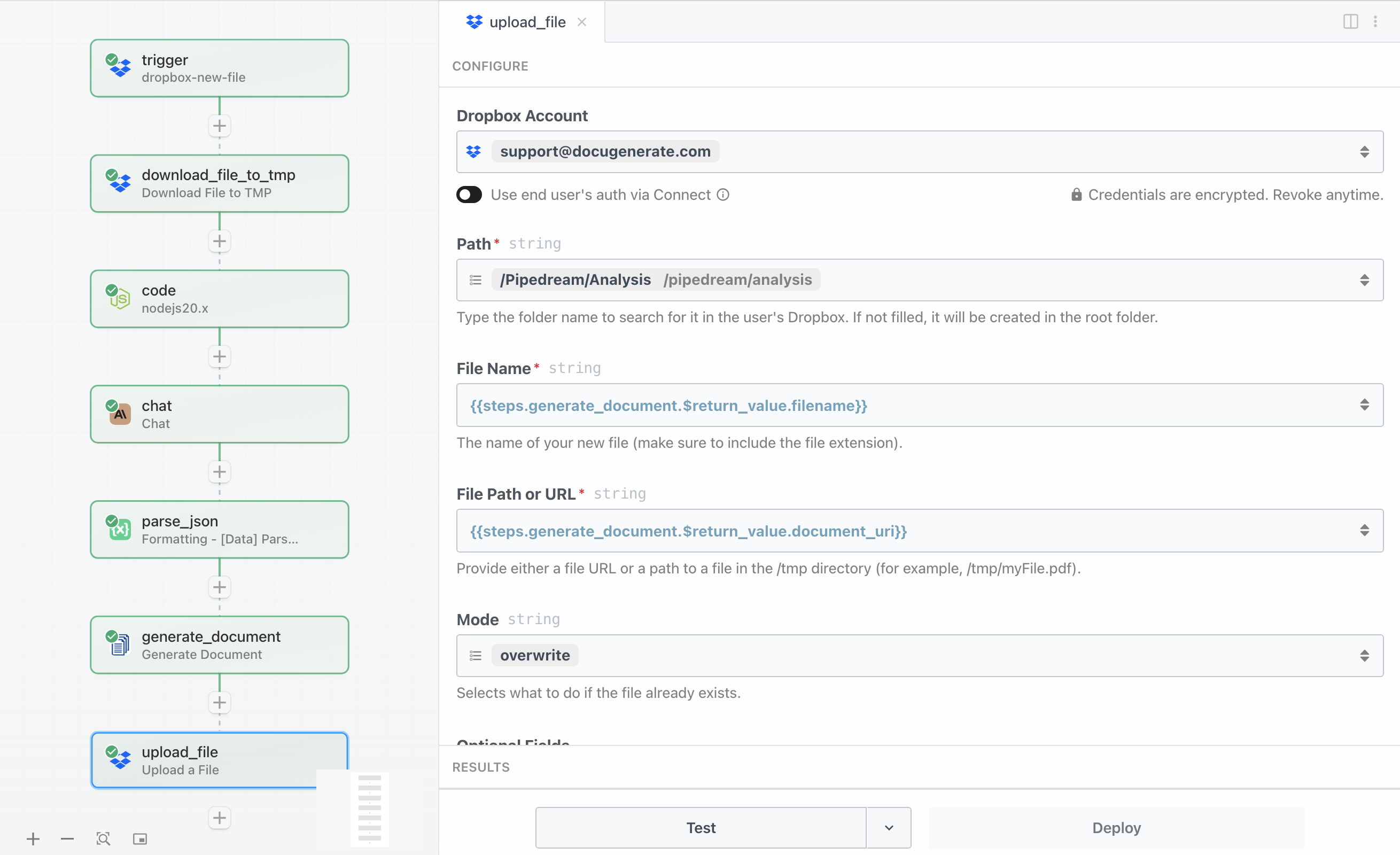
Die Konfiguration erfordert die Angabe des Zielpfads und des hochzuladenden Dateiinhalts:
- Path gibt den Zielordner
/Pipedream/Analysis an - File Name ist auf
{{steps.generate_document.$return_value.filename}} als Dateiname des generierten Dokuments gesetzt - File Path or URL referenziert den Wert
{{steps.generate_document.$return_value.document_uri}} aus dem vorherigen Schritt - Mode ist auf
overwrite gesetzt, um festzulegen, was zu tun ist, wenn die Datei bereits existiert
Nach dem Hochladen steht die Analyse sofort Ihrem Team zur Verfügung, und Sie können optional einen E-Mail-Benachrichtigungsschritt hinzufügen, um Einstellungsverantwortliche zu informieren, wenn eine neue Kandidatenzusammenfassung zur Überprüfung bereit ist.
Den Vollständigen Workflow Testen
Da alle Schritte konfiguriert sind, ist der Workflow bereit, Lebensläufe automatisch zu verarbeiten. Um ihn zu testen, laden Sie einfach eine Lebenslauf-PDF in den Ordner /Pipedream/Resumes in Ihrem Dropbox hoch. Der Workflow erkennt die neue Datei innerhalb von Sekunden und beginnt, sie durch jeden Schritt zu verarbeiten.
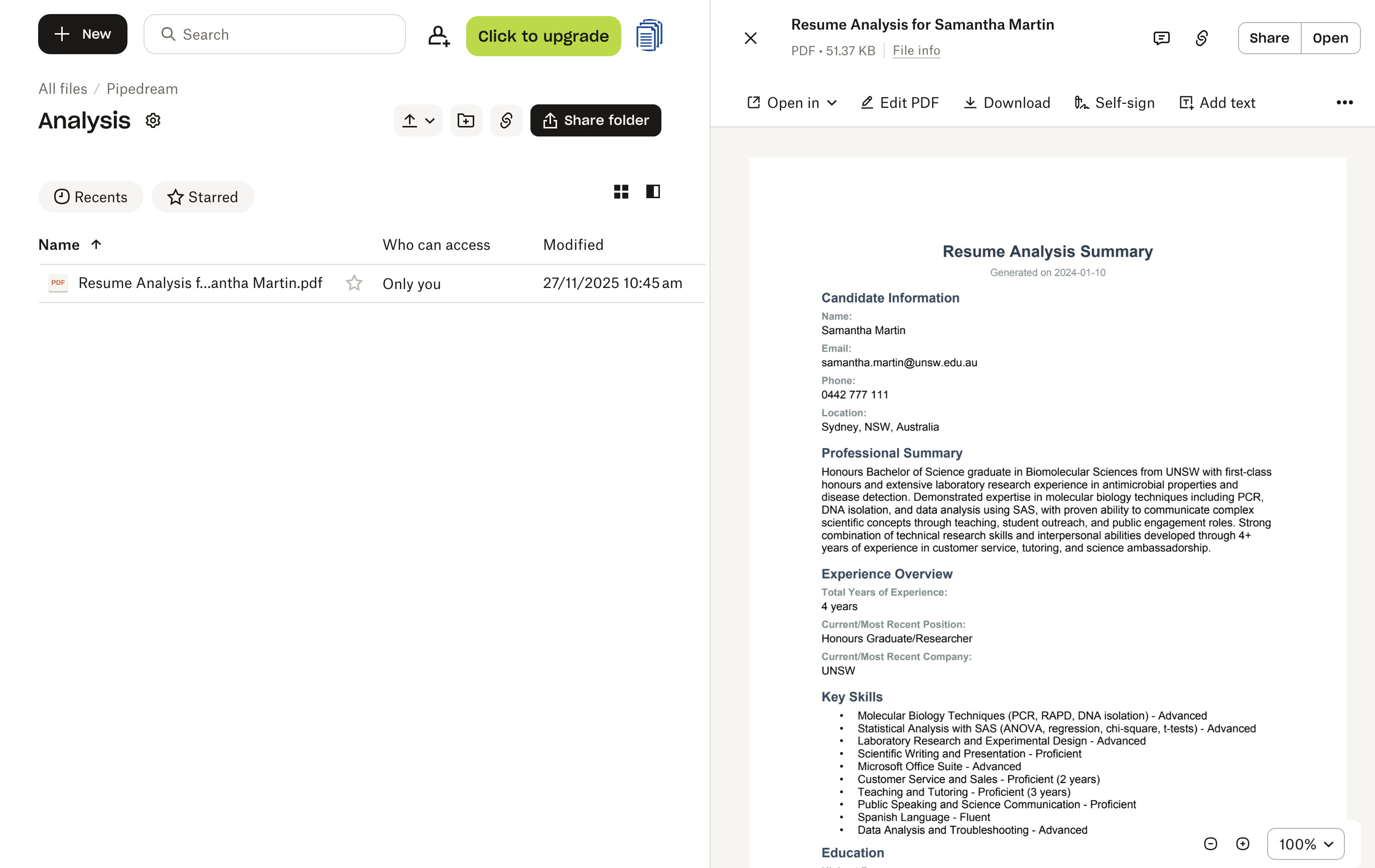
Sie können die Ausführung in Echtzeit über die Pipedream-Oberfläche überwachen, die den Datenfluss durch jeden Schritt zeigt. Nach Abschluss finden Sie die generierte Analyse-PDF in Ihrem Ordner /Pipedream/Analysis in Dropbox, bereit für die Überprüfung durch Ihr Einstellungsteam.
Den Workflow Erweitern
Der von uns aufgebaute Lebenslauf-Analyzer bietet eine solide Grundlage, aber es gibt viele Möglichkeiten, ihn zu erweitern, damit er besser zu Ihrem Einstellungsprozess passt. Hier sind einige praktische Erweiterungen, die Sie in Betracht ziehen könnten, um den Workflow noch wertvoller für Ihre Organisation zu machen.
Sie könnten einen E-Mail-Benachrichtigungsschritt hinzufügen, der Einstellungsverantwortliche sofort informiert, wenn eine neue Kandidatenanalyse bereit ist. Diese Benachrichtigung könnte wichtige Highlights aus Claudes Analyse enthalten, wie den Eignungswert und die berufliche Zusammenfassung, sowie einen direkten Link zum vollständigen PDF-Bericht in Dropbox. So entfällt die Notwendigkeit, dass Einstellungsverantwortliche den Ordner ständig auf neue Analysen prüfen müssen.
Eine weitere nützliche Erweiterung ist die Speicherung der strukturierten JSON-Daten in einer Datenbank oder Tabellenkalkulation. Durch Hinzufügen eines Schritts, der die geparsten Daten an Airtable, Google Sheets oder Ihr Bewerber-Tracking-System sendet, können Sie eine durchsuchbare Datenbank aller Kandidaten aufbauen. So können Sie Kandidaten einfach nach Fähigkeiten, Erfahrungsniveau oder Eignungswert filtern, wenn Sie nach bestimmten Qualifikationen suchen.
Sie könnten die Analyse auch basierend auf der zu besetzenden Stelle anpassen. Sie könnten verschiedene Vorlagen für verschiedene Rollen erstellen und den Dateinamen oder eine bestimmte Ordnerstruktur verwenden, um zu bestimmen, welche Vorlage genutzt werden soll. Lebensläufe in /Resumes/Engineering könnten beispielsweise eine Vorlage verwenden, die technische Fähigkeiten betont, während solche in /Resumes/Sales sich mehr auf Kommunikationsfähigkeiten und Vertriebserfahrung konzentrieren.
Fazit
Der Aufbau eines automatisierten Lebenslauf-Analyzers mit Pipedream, Claude und DocuGenerate zeigt, wie KI und Workflow-Automatisierung zeitaufwändige manuelle Prozesse in effiziente, konsistente Abläufe verwandeln können. Der von uns erstellte Workflow verarbeitet Lebensläufe in Sekunden, extrahiert aussagekräftige Erkenntnisse, die Menschen viel länger bräuchten, um sie zu identifizieren, und generiert Berichte, die Einstellungsentscheidungen erleichtern.
Dieser Ansatz ist besonders wertvoll, weil er Konsistenz bei der Kandidatenbewertung gewährleistet. Jeder Lebenslauf wird nach denselben Kriterien analysiert, was unbewusste Vorurteile reduziert und sicherstellt, dass alle Kandidaten fair bewertet werden. Das strukturierte Format der Analyseberichte erleichtert auch den direkten Vergleich von Kandidaten und die Identifizierung der vielversprechendsten Bewerber für Ihre offenen Stellen.
Das hier demonstrierte Workflow-Muster geht über die Lebenslaufanalyse hinaus. Derselbe Ansatz zur Textextraktion aus Dokumenten, zur KI-gestützten Analyse und Strukturierung des Inhalts sowie zur Generierung formatierter Berichte kann auf viele andere Dokumentenverarbeitungsszenarien angewendet werden. Ob Sie Verträge analysieren, Kundenfeedback verarbeiten oder Daten aus Forschungsarbeiten extrahieren – der zentrale Workflow bleibt ähnlich, mit Anpassungen am Analyse-Prompt und der Ausgabevorlage.
Ressourcen