Introductie
Cv-screening is een van de meest tijdrovende aspecten van het wervingsproces. HR-teams besteden vaak uren aan het beoordelen van cv’s om belangrijke informatie te extraheren, kandidaten te evalueren, en samenvattingen voor hiring managers voor te bereiden. In deze tutorial bouwen we een geautomatiseerde cv-analysator die dit werk voor u verzorgt, waarbij we de kracht van workflowautomatisering met Pipedream, intelligente analyse met Claude AI, en professionele PDF-generatie met DocuGenerate combineren.
De workflow werkt automatisch telkens wanneer een nieuw cv wordt toegevoegd aan een Dropbox-map. Deze extraheert de tekst uit het cv, gebruikt Claude om de ervaring en kwalificaties van de kandidaat te analyseren, genereert een gestructureerde samenvatting met belangrijke inzichten, en maakt een professioneel PDF-rapport dat uw wervingsteam onmiddellijk kan beoordelen. Het gehele proces duurt slechts enkele seconden en vereist geen handmatige tussenkomst.
Deze aanpak is bijzonder waardevol voor organisaties die snel meerdere cv’s moeten verwerken, terwijl consistentie in de kandidaatevaluatie behouden blijft. Door het analyseformaat te standaardiseren en AI te benutten om inzichten te extraheren, kunt u uw tijd richten op het interviewen van de meest veelbelovende kandidaten in plaats van uren te besteden aan de eerste screening.
De Workflow Begrijpen
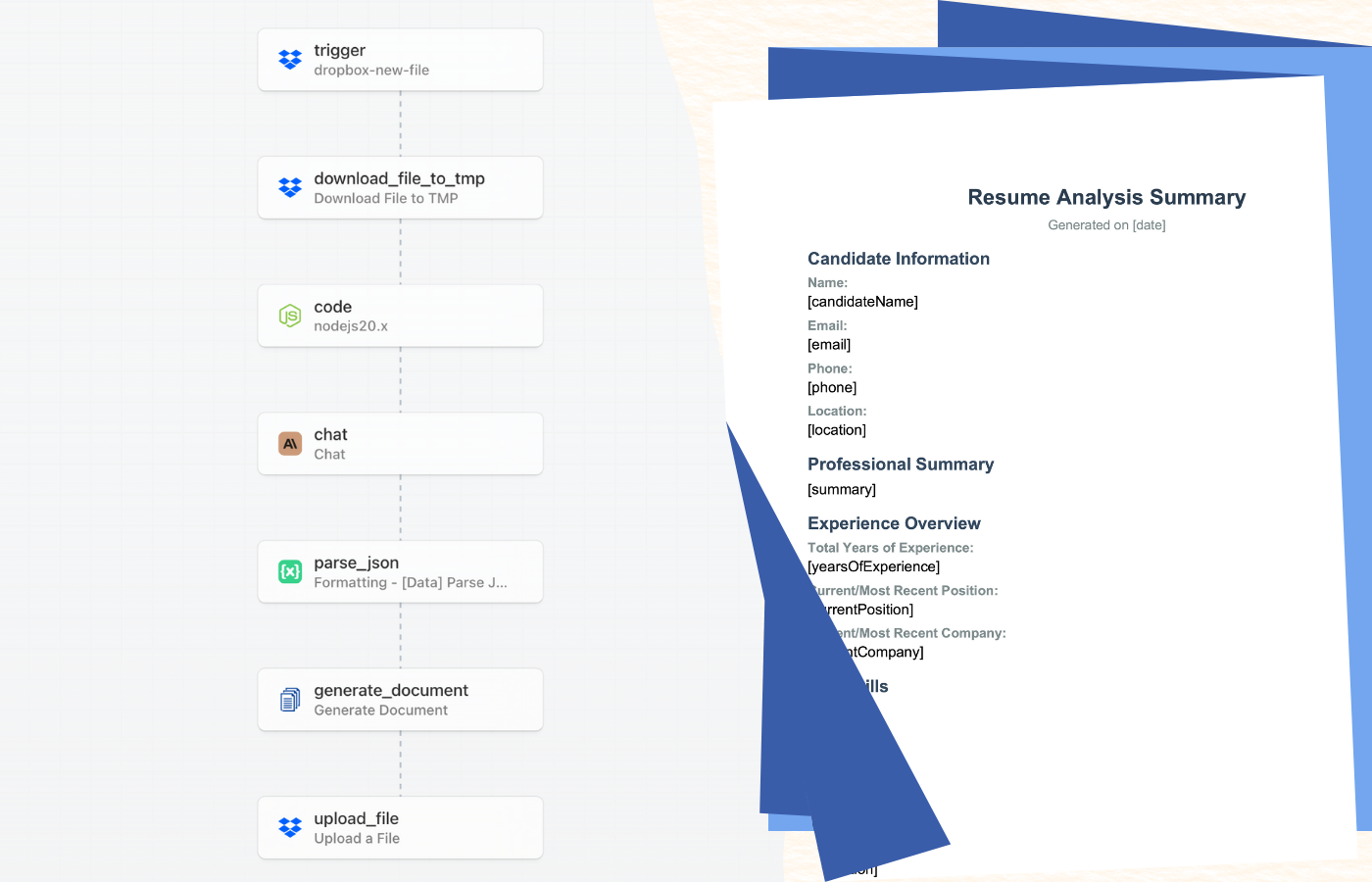
De volledige workflow bestaat uit zeven verbonden stappen die samenwerken om een ruw cv om te zetten naar een gestructureerd analyserapport. Zo verloopt het proces van begin tot eind:
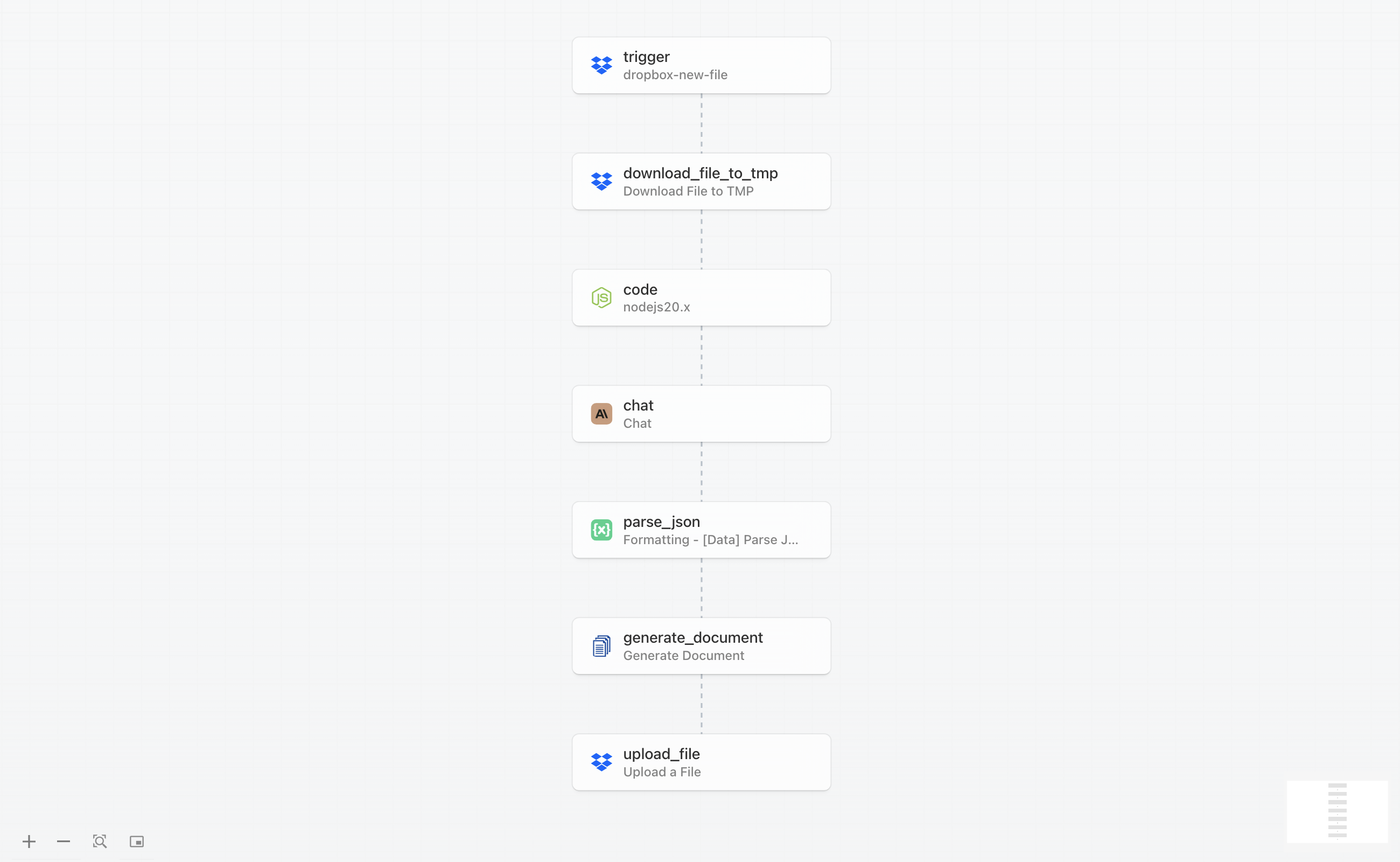
De workflow begint wanneer u een cv uploadt naar een gecontroleerde Dropbox-map. Pipedream detecteert het nieuwe bestand, downloadt het, en extraheert de tekstinhoud uit de PDF. Deze tekst wordt vervolgens naar Claude AI gestuurd met specifieke instructies om het cv te analyseren en belangrijke informatie te extraheren, zoals werkervaring, vaardigheden, opleiding, en opmerkelijke prestaties. Claude retourneert een gestructureerd JSON-antwoord met alle geëxtraheerde data.
De JSON-data wordt vervolgens doorgegeven aan DocuGenerate, samen met een vooraf ontworpen sjabloon, om een professionele PDF-samenvatting te genereren. Zodra het document is gemaakt, wordt het automatisch teruggeüpload naar Dropbox in een aangewezen map, waar uw wervingsteam er toegang toe heeft. Het gehele proces wordt in minder dan een minuut voltooid, en u kunt meerdere cv’s tegelijk verwerken door ze simpelweg naar de triggermap te uploaden.
Het Documentsjabloon Instellen
Voordat we de Pipedream-workflow bouwen, moeten we een sjabloon maken dat onze cv-analyserapporten opmaakt. Het sjabloon gebruikt de merge-tag-syntax van DocuGenerate om te definiëren waar data uit de analyse van Claude moet verschijnen in het uiteindelijke document. Dit zorgt ervoor dat elke kandidaatsamenvatting een consistent, professioneel formaat volgt.
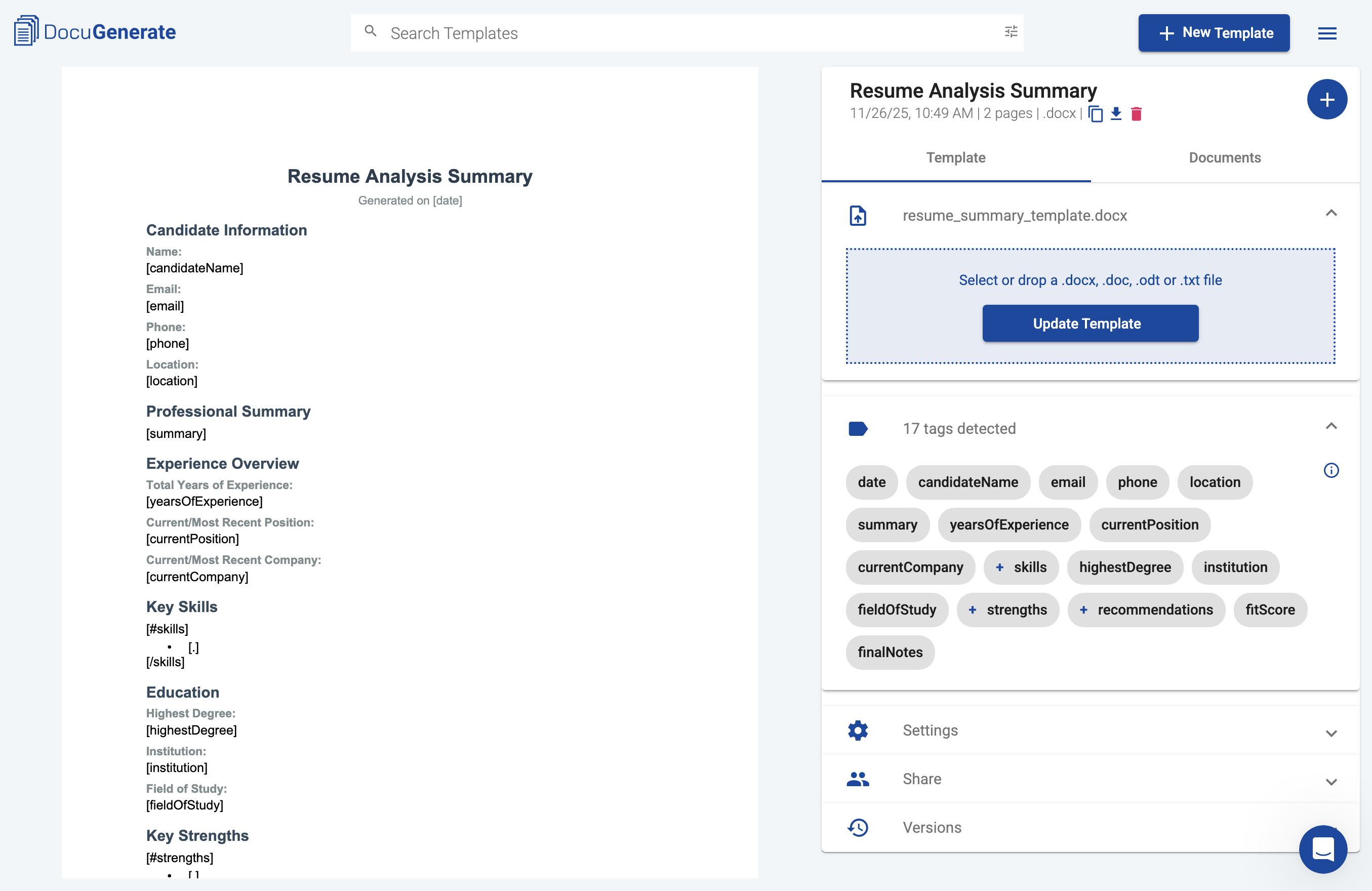
Het sjabloon bevat secties voor kandidaatinformatie (naam, e-mail, telefoon, locatie), een professionele samenvatting, ervaringsoverzicht, belangrijke vaardigheden, opleiding, sterke punten, interviewaanbevelingen, en een algemene beoordeling met een geschiktheidsscore. Sommige secties, zoals vaardigheden, sterke punten, en aanbevelingen, gebruiken lijstsyntax om meerdere items uit arrays in de data weer te geven. De sectie met vaardigheden gebruikt bijvoorbeeld [#skills] om de lus te starten, [.] om elke vaardigheid als opsommingsteken weer te geven, en [/skills] om de lus te beëindigen.
U kunt het volledige sjabloon downloaden en uploaden naar uw DocuGenerate-account. Noteer na het uploaden de sjabloonnaam of -ID, aangezien u deze informatie nodig heeft bij het configureren van de stap voor documentgeneratie in de workflow. Nu het sjabloon klaar is, kunnen we de Pipedream-workflow bouwen die het volledige analyseproces zal automatiseren.
De workflow begint met een Dropbox-trigger die een specifieke map controleert op nieuwe bestanden. Deze trigger is het beginpunt dat de gehele automatisering activeert telkens wanneer een cv wordt geüpload. Om deze trigger te configureren, moet u uw Dropbox-account koppelen aan Pipedream en opgeven welke map moet worden gecontroleerd.
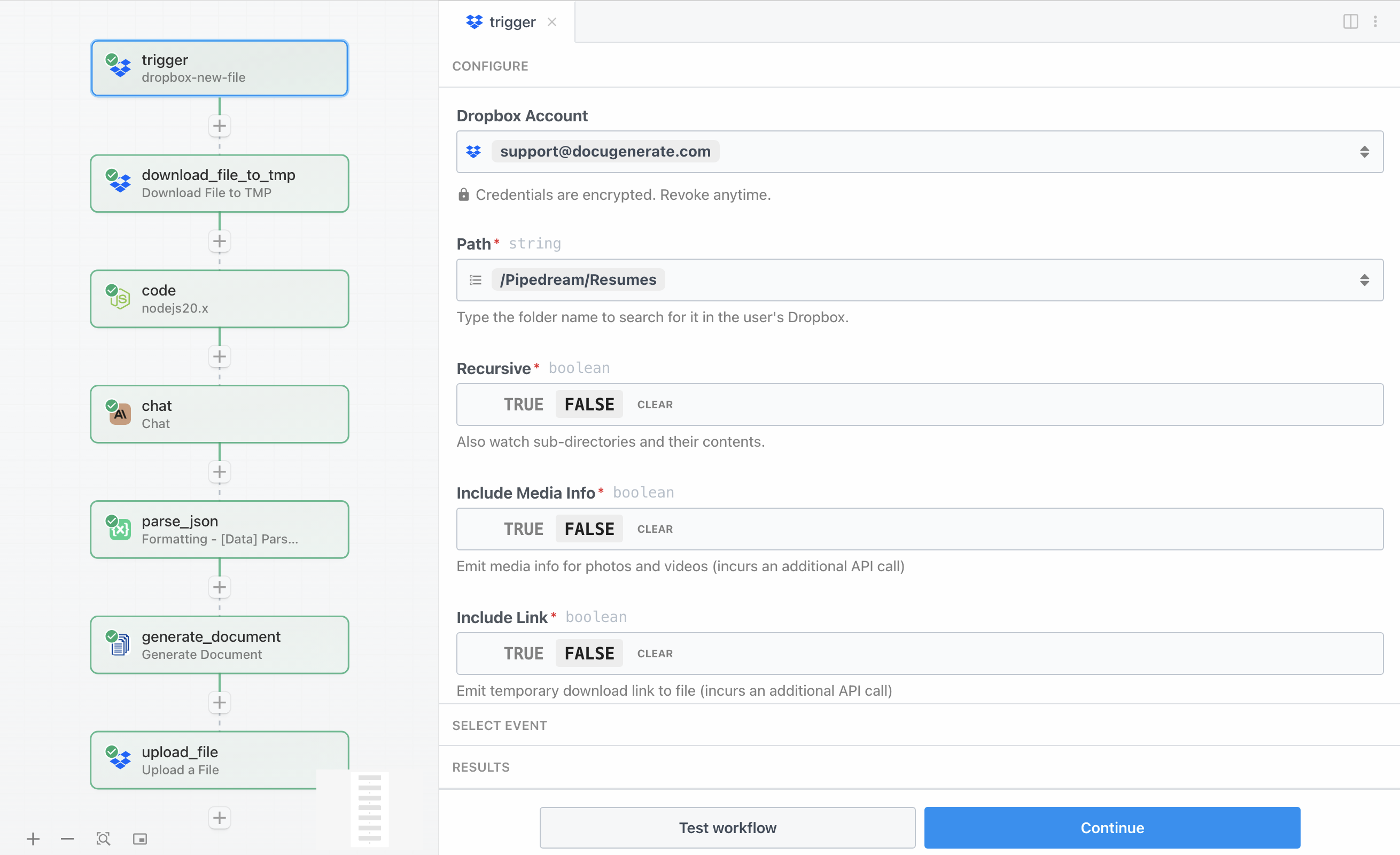
Voor deze tutorial controleren we een map genaamd /Pipedream/Resumes. Wanneer u de trigger test met een voorbeeld-cv, ziet u dat deze metadata over het bestand retourneert, inclusief de bestandsnaam, het pad, de grootte, en wijzigingsdatums. Het is echter belangrijk om op te merken dat de trigger alleen deze metadata biedt en niet de daadwerkelijke bestandsinhoud. Daarom hebben we een aparte stap nodig om het bestand te downloaden, die we configureren in de volgende sectie.
De trigger wordt onmiddellijk geactiveerd wanneer een nieuw bestand wordt gedetecteerd, waardoor de workflow reageert op uw wervingsbehoeften. U kunt de hele dag door cv’s uploaden, en elk cv wordt automatisch verwerkt zonder enige handmatige tussenkomst. Deze realtime verwerking zorgt ervoor dat kandidaatsamenvattingen zo snel mogelijk beschikbaar zijn voor uw team.
Het Cv-Bestand Downloaden
Nadat de trigger een nieuw bestand detecteert, moeten we de bestandsinhoud daadwerkelijk downloaden voordat we er tekst uit kunnen extraheren. De actie Download File to TMP haalt het cv op van Dropbox en slaat het op in de tijdelijke opslag van Pipedream, waar volgende stappen er toegang toe hebben.
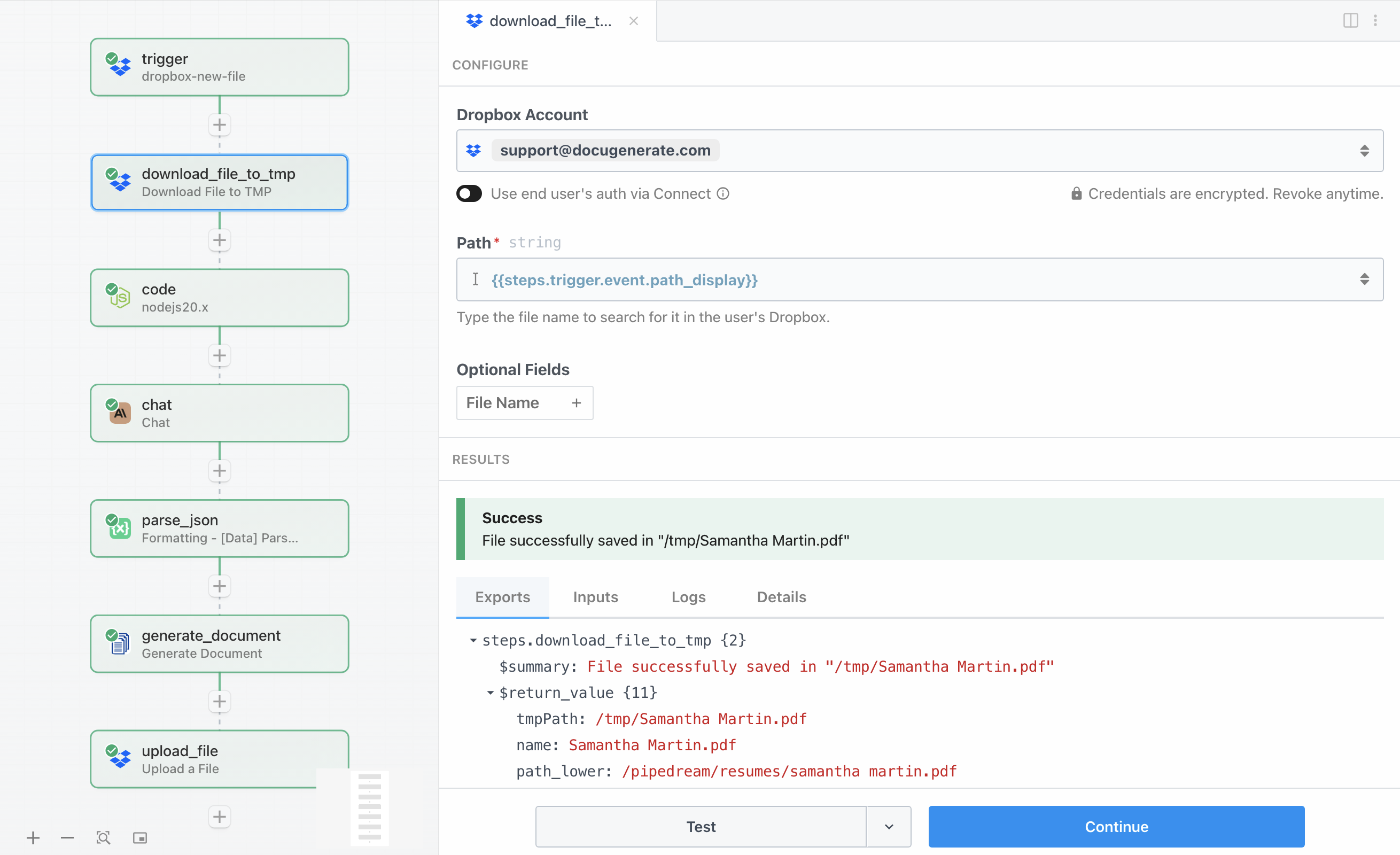
De configuratie is eenvoudig. De parameter Path gebruikt {{steps.trigger.event.path_display}} om te verwijzen naar het bestandspad dat door de trigger is vastgelegd. Deze actie downloadt het bestand en retourneert een object met het tijdelijke bestandspad in de eigenschap tmpPath. Het bestand blijft gedurende de uitvoering van de workflow in tijdelijke opslag, wat perfect is voor verwerking en het vervolgens verwijderen nadat de workflow is voltooid.
Het gedownloade bestand is nu klaar voor tekstextractie. Het tijdelijke bestandspad wordt in de volgende stap gebruikt om de PDF-inhoud te lezen en om te zetten naar tekst die Claude kan analyseren.
Nu het cv is gedownload naar tijdelijke opslag, moeten we de tekstinhoud uit het PDF-bestand extraheren. Deze stap gebruikt een Node.js-codeblok met de pdf-parse-bibliotheek om de PDF te lezen en om te zetten naar platte tekst die Claude kan analyseren.
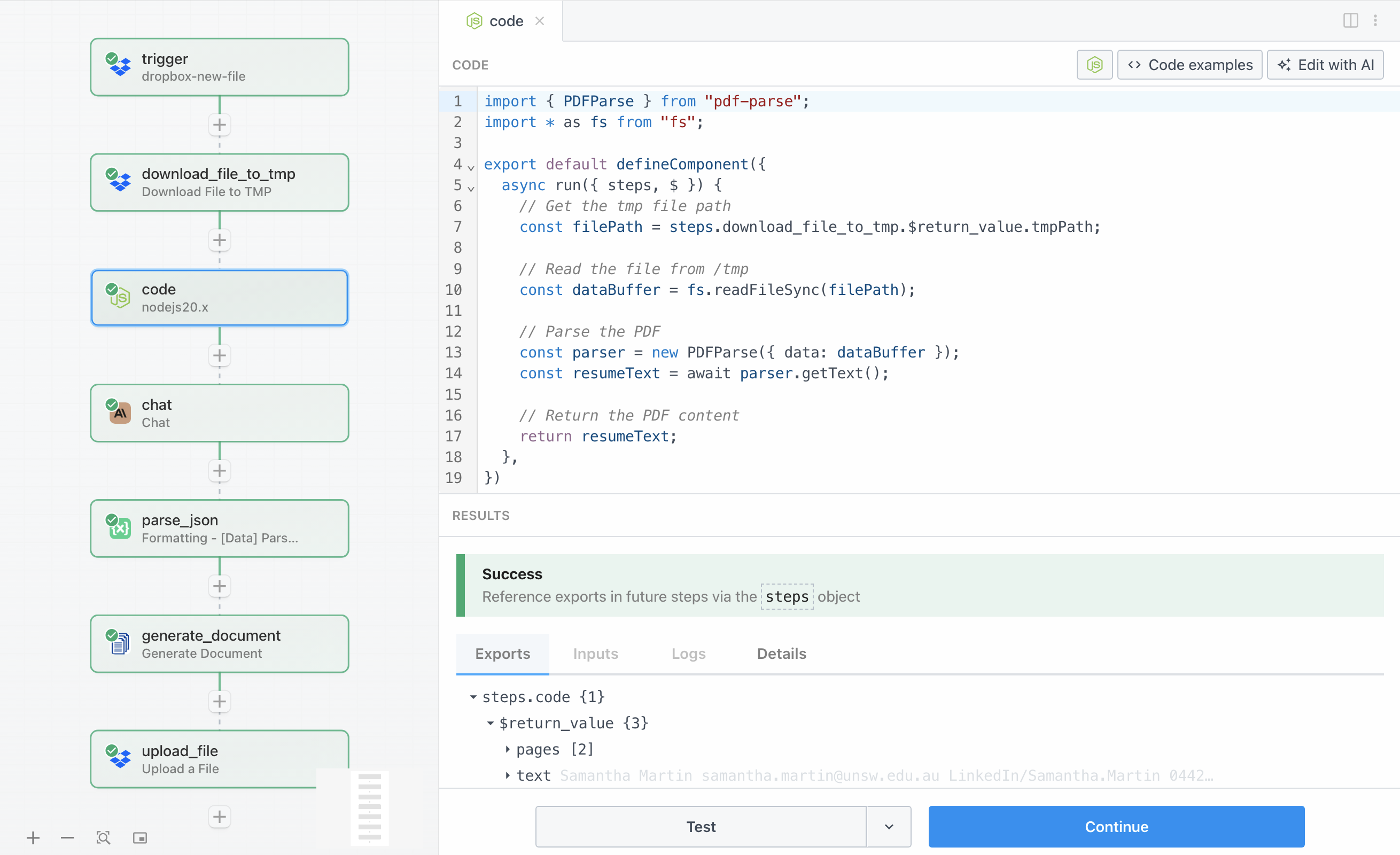
De code leest het bestand van het tijdelijke pad met behulp van de ingebouwde fs-module van Node.js, en geeft vervolgens de bestandsbuffer door aan pdf-parse voor verwerking. De bibliotheek verzorgt de complexiteit van het parsen van PDF’s en retourneert de geëxtraheerde tekst als een string.
import { PDFParse } from "pdf-parse";
import * as fs from "fs";
export default defineComponent({
async run({ steps, $ }) {
// Get the tmp file path
const filePath = steps.download_file_to_tmp.$return_value.tmpPath;
// Read the file from /tmp
const dataBuffer = fs.readFileSync(filePath);
// Parse the PDF
const parser = new PDFParse({ data: dataBuffer });
const resumeText = await parser.getText();
// Return the PDF content
return resumeText;
},
})
De geëxtraheerde tekst is nu beschikbaar in resumeText en klaar om in de volgende stap door Claude te worden geanalyseerd.
Het Cv Analyseren met Claude
Dit is waar de intelligentie plaatsvindt. De Claude-API-stap stuurt de geëxtraheerde cv-tekst naar de Claude AI van Anthropic met gedetailleerde instructies om de content te analyseren en gestructureerde data in JSON-formaat te retourneren. Claude onderzoekt het cv en extraheert belangrijke informatie, waaronder werkervaring, vaardigheden, opleiding, en biedt inzichten die doorgaans een handmatige beoordeling zouden vereisen.
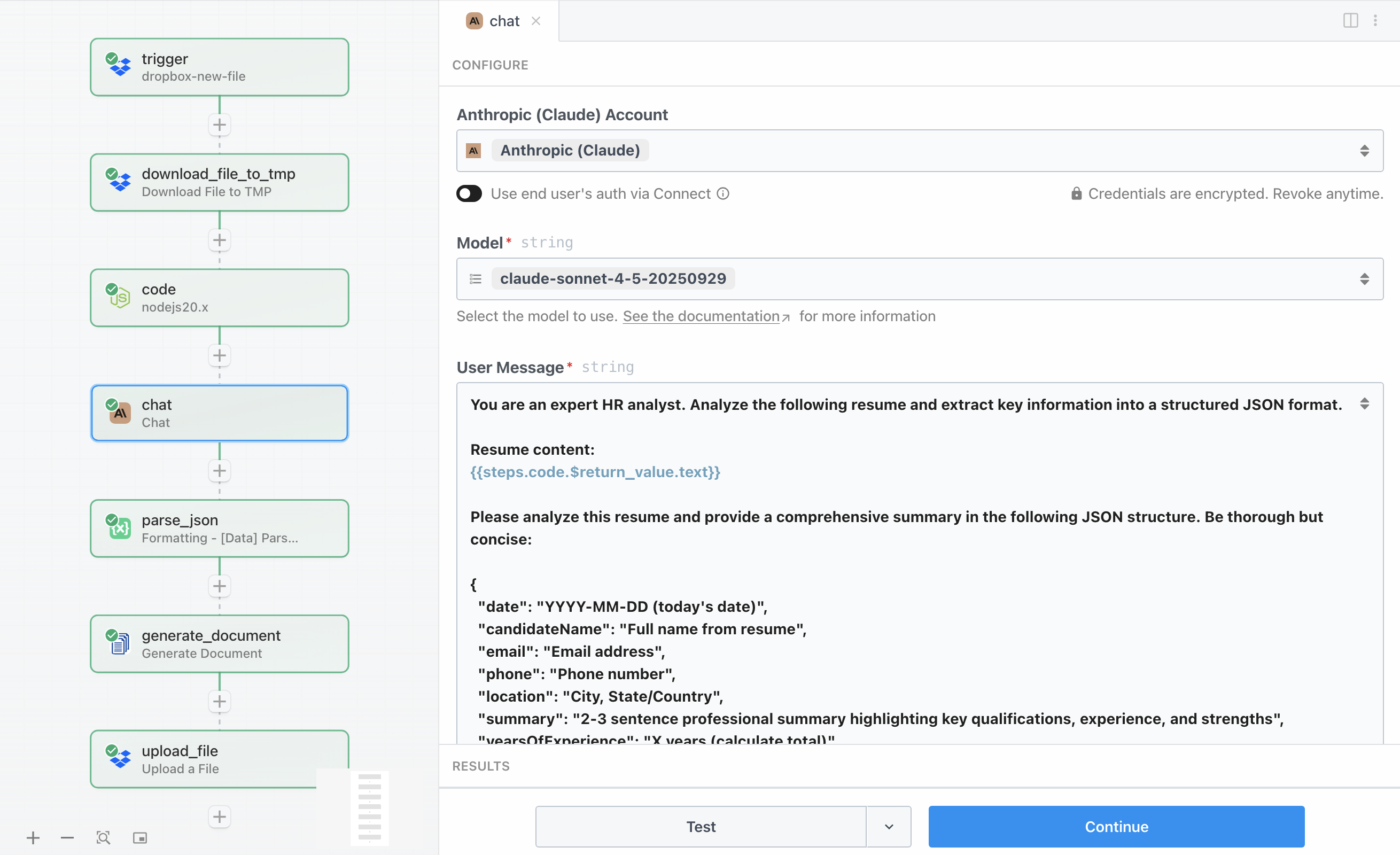
Voor de configuratie van de actie Chat with Anthropic (Claude) heeft u uw Anthropic-API-sleutel nodig, die u kunt verkrijgen via uw Anthropic-account. Het verzoek gebruikt het model claude-sonnet-4-5-20250929, dat een uitstekende balans biedt tussen snelheid, kosten, en analytisch vermogen voor deze taak. De parameter Maximum Tokens to Sample is ingesteld op 4096, wat Claude voldoende ruimte geeft om een uitgebreide analyse te retourneren met alle velden die we nodig hebben.
De prompt is zorgvuldig gestructureerd om Claude te sturen bij het extraheren van specifieke informatie en het opmaken ervan als geldige JSON. Dit is de volledige prompt die Claude instrueert wat te analyseren en hoe het antwoord moet worden gestructureerd:
You are an expert HR analyst. Analyze the following resume and extract key information into a structured JSON format.
Resume content:
{{steps.code.$return_value.text}}
Please analyze this resume and provide a comprehensive summary in the following JSON structure. Be thorough but concise:
{
"date": "YYYY-MM-DD (today's date)",
"candidateName": "Full name from resume",
"email": "Email address",
"phone": "Phone number",
"location": "City, State/Country",
"summary": "2-3 sentence professional summary highlighting key qualifications, experience, and strengths",
"yearsOfExperience": "X years (calculate total)",
"currentPosition": "Most recent job title",
"currentCompany": "Most recent company name",
"skills": [
"List 6-10 key technical and professional skills with proficiency levels where relevant"
],
"highestDegree": "Degree name (e.g., Bachelor of Science in Computer Science)",
"institution": "University/College name",
"fieldOfStudy": "Major/Field",
"strengths": [
"List 4-6 key strengths based on achievements, projects, and experience"
],
"recommendations": [
"List 4-5 specific interview questions or topics to explore based on their unique experience"
],
"fitScore": "Rate 1-10 based on overall qualifications and experience",
"finalNotes": "2-3 sentence overall assessment and hiring recommendation"
}
IMPORTANT INSTRUCTIONS:
- Extract all information directly from the resume
- If any field is not available in the resume, use "Not specified" or an empty array []
- For skills, include proficiency levels when they can be inferred from years of experience or explicit mentions
- Make the summary compelling but accurate
- Base the fitScore on years of experience, skill diversity, education, and career progression
- Ensure all JSON is properly formatted with no syntax errors
- Return ONLY the JSON object, no additional text or markdown formatting
CRITICAL OUTPUT REQUIREMENTS:
- Return ONLY the raw JSON object
- Do NOT wrap the JSON in markdown code blocks
- Do NOT include ```json or ``` markers
- Do NOT add any explanatory text before or after the JSON
- The response must start with { and end with }
- The entire response must be valid, parseable JSON
Claude verwerkt de cv-tekst en retourneert een JSON-object met alle geëxtraheerde informatie. Het antwoord omvat alles, van basale contactgegevens tot inzichtelijke aanbevelingen voor interviewvragen op basis van de unieke ervaring van de kandidaat. Dit gestructureerde formaat maakt het eenvoudig om de data door te geven aan DocuGenerate voor documentgeneratie in de volgende stap.
Het JSON-Antwoord Parsen
Claude retourneert zijn analyse als een JSON-string, maar we moeten dit omzetten naar een gestructureerd object waarmee we in volgende stappen kunnen werken. De ingebouwde actie Parse JSON van Pipedream, te vinden onder Formatting → Data, verzorgt deze conversie automatisch.
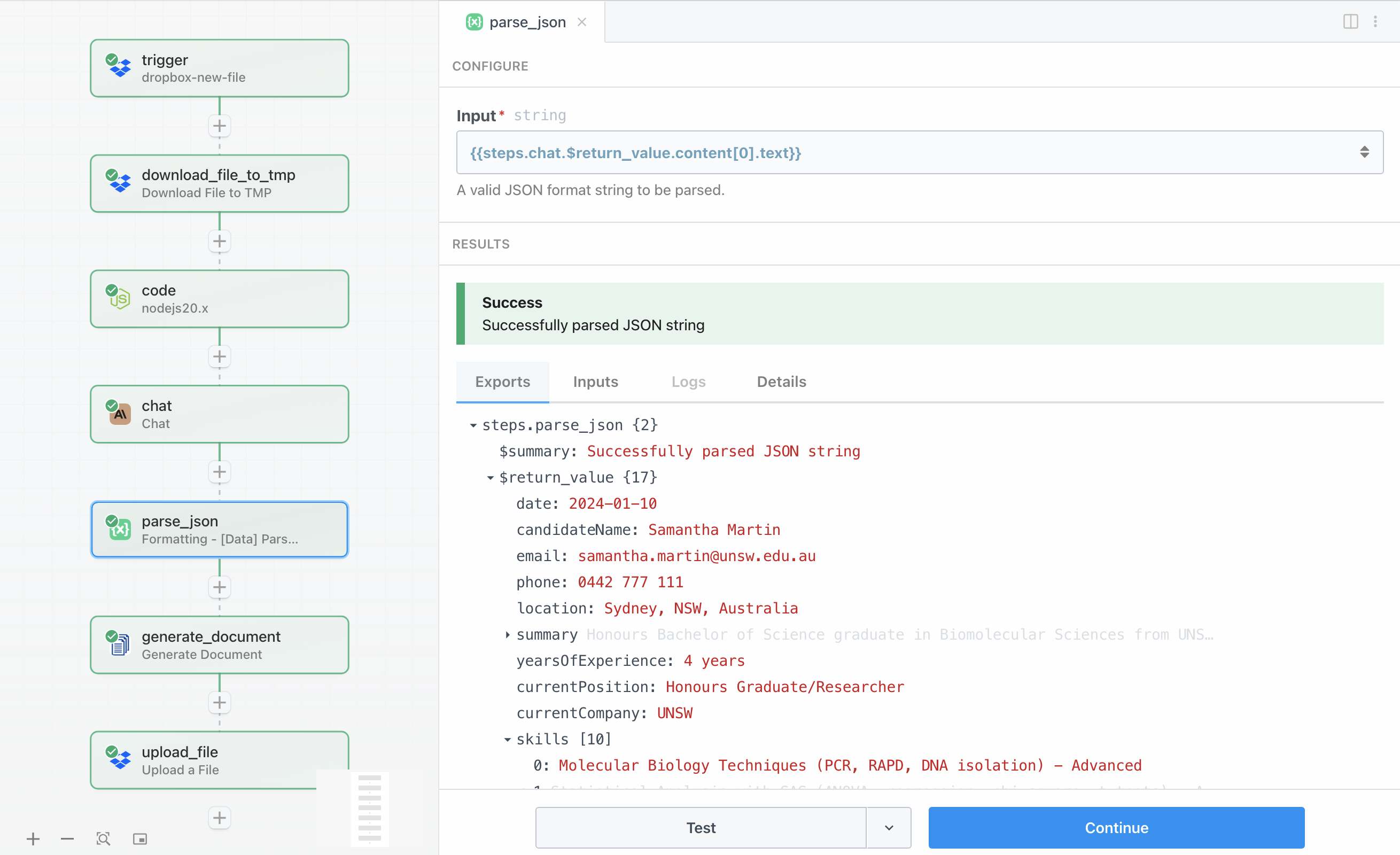
De configuratie neemt simpelweg het antwoord van Claude uit {{steps.chat.$return_value.content[0].text}} en parseert dit naar een gestructureerd object. Deze geparseerde data wordt beschikbaar voor alle volgende stappen in de workflow, waardoor we kunnen verwijzen naar specifieke velden zoals {{steps.parse_json.$return_value.candidateName}} wanneer we ze nodig hebben.
Het parsen van de data in afzonderlijke velden is bijzonder nuttig voor dynamische bestandsbenaming en voor het doorgeven van de complete dataset aan DocuGenerate. Het geparseerde object bevat alle velden die in ons sjabloon zijn gedefinieerd: kandidaatinformatie, samenvatting, vaardighedenarray, sterke-puntenarray, aanbevelingenarray, en de algemene beoordeling.
Het Samenvattingsdocument Genereren
Nu de geanalyseerde data beschikbaar is als een gestructureerd object, zijn we klaar om de professionele PDF-samenvatting te genereren. Deze stap gebruikt de DocuGenerate App op Pipedream om de data samen te voegen met ons sjabloon en een opgemaakt document te maken.
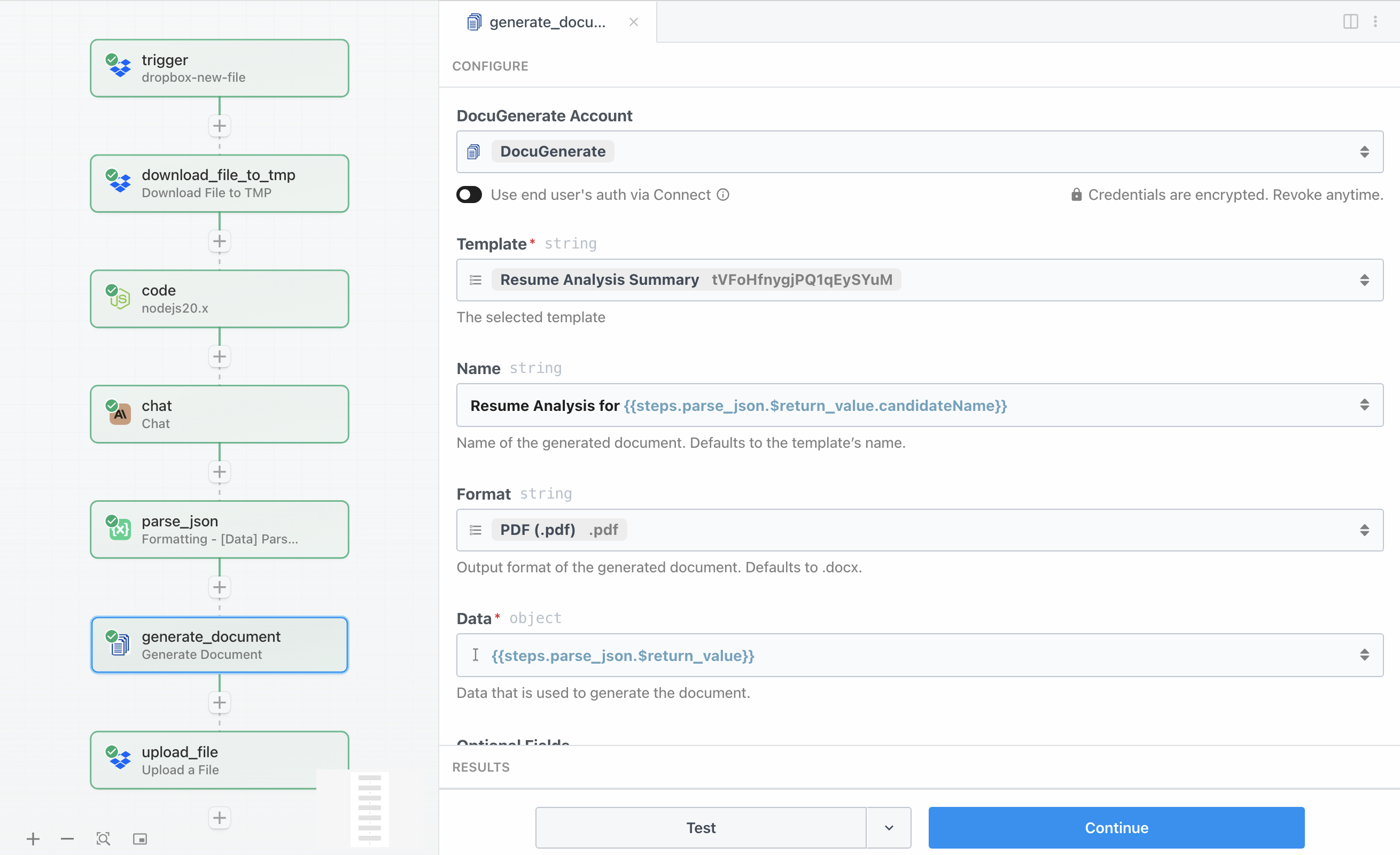
U heeft uw DocuGenerate API-sleutel nodig om een verbinding tot stand te brengen, die u kunt vinden in uw accountinstellingen. De configuratie van de actie omvat verschillende belangrijke parameters:
- Template geeft het sjabloon Resume Analysis Summary op uit de installatiesectie
- Name gebruikt
Resume Analysis for {{steps.parse_json.$return_value.candidateName}} om een dynamische bestandsnaam te maken op basis van de naam van de kandidaat - Format is ingesteld op
PDF (.pdf) om een PDF-document te genereren - Data bevat het volledige geparseerde JSON-object
{{steps.parse_json.$return_value}} van Claude met alle kandidaatinformatie
De API verwerkt dit verzoek en retourneert een antwoord met een veld document_uri, wat een URL is die verwijst naar het gegenereerde PDF-document.
De Analyse Uploaden naar Dropbox
De laatste stap voltooit de workflow door de gegenereerde PDF-analyse terug te uploaden naar Dropbox, waar uw wervingsteam er toegang toe heeft. De actie Upload a File slaat het document op in een aangewezen map, en organiseert alle kandidaatanalyses op één locatie.
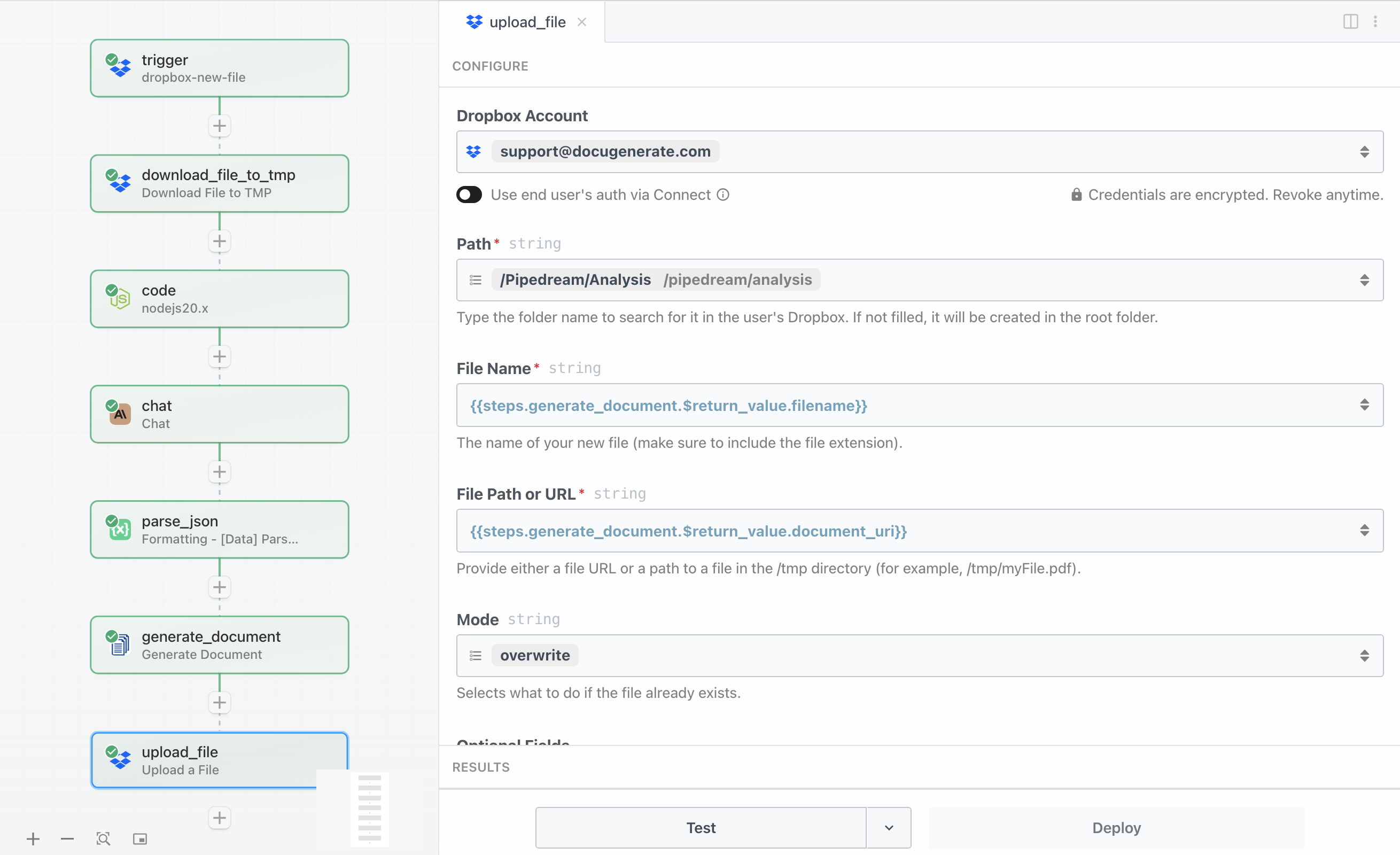
De configuratie vereist het opgeven van het doelpad en de bestandsinhoud die moet worden geüpload:
- Path geeft de doelmap
/Pipedream/Analysis op - File Name is ingesteld op
{{steps.generate_document.$return_value.filename}} als de bestandsnaam van het gegenereerde document - File Path or URL verwijst naar de waarde
{{steps.generate_document.$return_value.document_uri}} uit de vorige stap - Mode is ingesteld op
overwrite om te bepalen wat er moet gebeuren als het bestand al bestaat
Zodra het is geüpload, is de analyse onmiddellijk beschikbaar voor uw team, en kunt u optioneel een stap voor e-mailmeldingen toevoegen om hiring managers te waarschuwen wanneer een nieuwe kandidaatsamenvatting klaar is om te worden beoordeeld.
De Volledige Workflow Testen
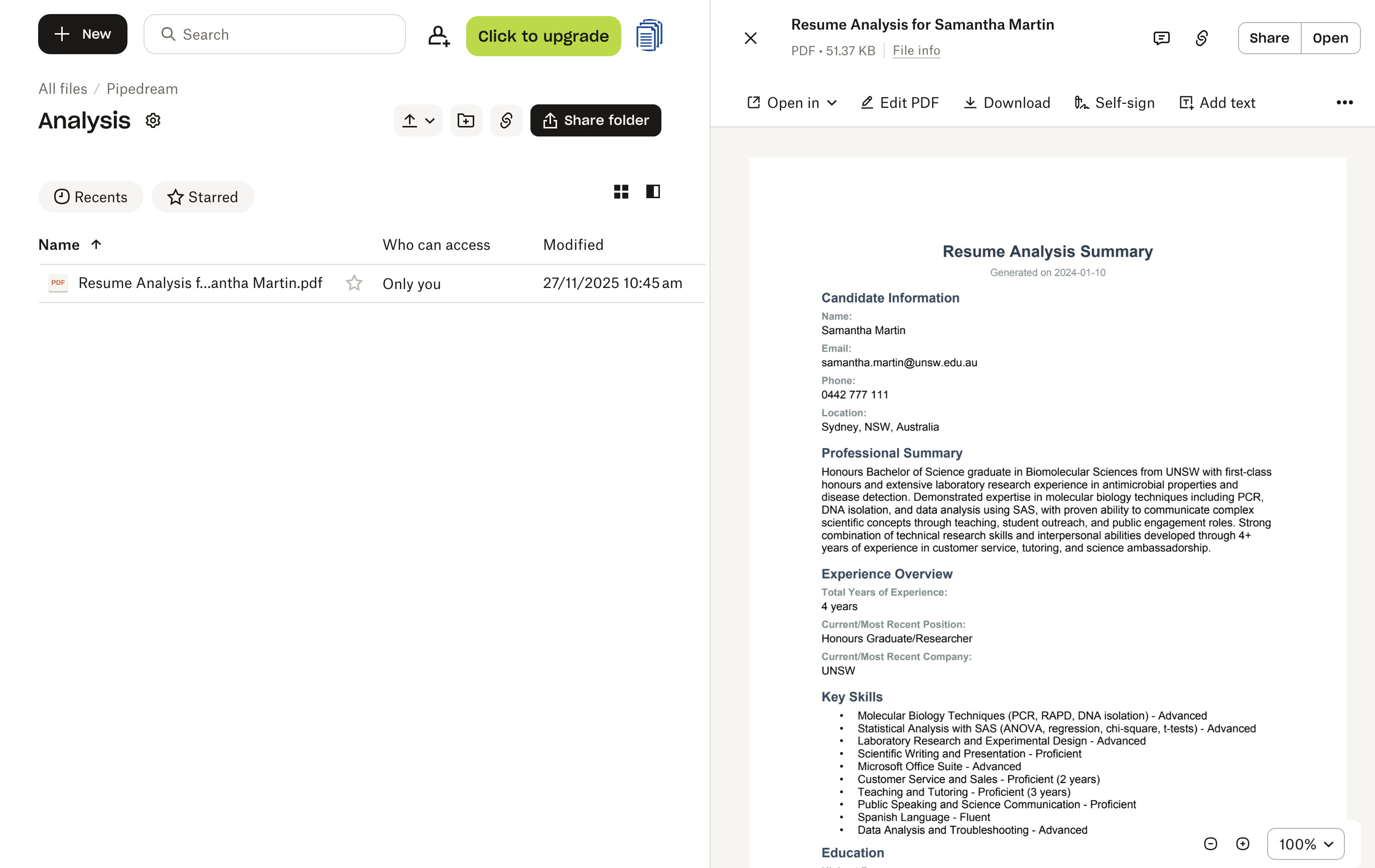
Nu alle stappen zijn geconfigureerd, is de workflow klaar om cv’s automatisch te verwerken. Om dit te testen, uploadt u simpelweg een cv-PDF naar de map /Pipedream/Resumes in uw Dropbox. De workflow detecteert het nieuwe bestand binnen enkele seconden en begint met de verwerking via elke stap.
U kunt de uitvoering in realtime volgen via de interface van Pipedream, die toont hoe de data door elke stap stroomt. Zodra dit is voltooid, vindt u de gegenereerde analyse-PDF in uw map /Pipedream/Analysis in Dropbox, klaar voor beoordeling door uw wervingsteam.
De Workflow Uitbreiden
De cv-analysator die we hebben gebouwd, biedt een solide basis, maar er zijn veel manieren waarop u deze kunt uitbreiden om beter aan te sluiten bij uw wervingsproces. Hier zijn enkele praktische verbeteringen die u zou kunnen overwegen toe te voegen om de workflow nog waardevoller te maken voor uw organisatie.
U zou een stap voor e-mailmeldingen kunnen toevoegen die hiring managers onmiddellijk waarschuwt wanneer een nieuwe kandidaatanalyse klaar is. Deze melding zou belangrijke hoogtepunten uit de analyse van Claude kunnen bevatten, zoals de geschiktheidsscore en professionele samenvatting, samen met een directe link naar het volledige PDF-rapport in Dropbox. Dit elimineert de noodzaak voor hiring managers om voortdurend de map te controleren op nieuwe analyses.
Een andere nuttige uitbreiding is het opslaan van de gestructureerde JSON-data in een database of spreadsheet. Door een stap toe te voegen die de geparseerde data verstuurt naar Airtable, Google Sheets, of uw applicant tracking system, kunt u een doorzoekbare database van alle kandidaten bouwen. Dit maakt het eenvoudig om kandidaten te filteren op vaardigheden, ervaringsniveau, of geschiktheidsscore wanneer u op zoek bent naar specifieke kwalificaties.
U wilt de analyse mogelijk ook aanpassen op basis van de functie waarvoor u werft. U zou verschillende sjablonen kunnen maken voor verschillende functies en de bestandsnaam of een aangewezen mapstructuur kunnen gebruiken om te bepalen welk sjabloon moet worden gebruikt. Cv’s in /Resumes/Engineering zouden bijvoorbeeld een sjabloon kunnen gebruiken dat de nadruk legt op technische vaardigheden, terwijl die in /Resumes/Sales zich meer zouden kunnen richten op communicatievaardigheden en dealervaring.
Conclusie
Het bouwen van een geautomatiseerde cv-analysator met Pipedream, Claude, en DocuGenerate toont hoe AI en workflowautomatisering tijdrovende handmatige processen kunnen transformeren in efficiënte, consistente bewerkingen. De workflow die we hebben gemaakt, verwerkt cv’s in seconden, extraheert betekenisvolle inzichten die mensen veel langer zouden kosten om te identificeren, en genereert rapporten die wervingsbeslissingen eenvoudiger maken.
Deze aanpak is bijzonder waardevol, omdat het consistentie behoudt in de kandidaatevaluatie. Elk cv wordt geanalyseerd met dezelfde criteria, wat onbewuste vooroordelen vermindert en ervoor zorgt dat alle kandidaten eerlijk worden beoordeeld. Het gestructureerde formaat van de analyserapporten maakt het ook eenvoudiger om kandidaten naast elkaar te vergelijken en de meest veelbelovende sollicitanten voor uw openstaande functies te identificeren.
Het workflowpatroon dat we hier hebben gedemonstreerd, gaat verder dan alleen cv-analyse. Dezelfde aanpak van het extraheren van tekst uit documenten, het gebruiken van AI om de content te analyseren en te structureren, en het genereren van opgemaakte rapporten, kan worden toegepast op veel andere documentverwerkingsscenario’s. Of u nu contracten analyseert, klantfeedback verwerkt, of data extraheert uit onderzoekspapers, de kernworkflow blijft vergelijkbaar met aanpassingen aan de analyseprompt en het uitvoersjabloon.
Bronnen